
ElasticSearch - 底层原理
测试数据

"index": false 不生成倒排索引
"doc_values": false 不生成正排索引
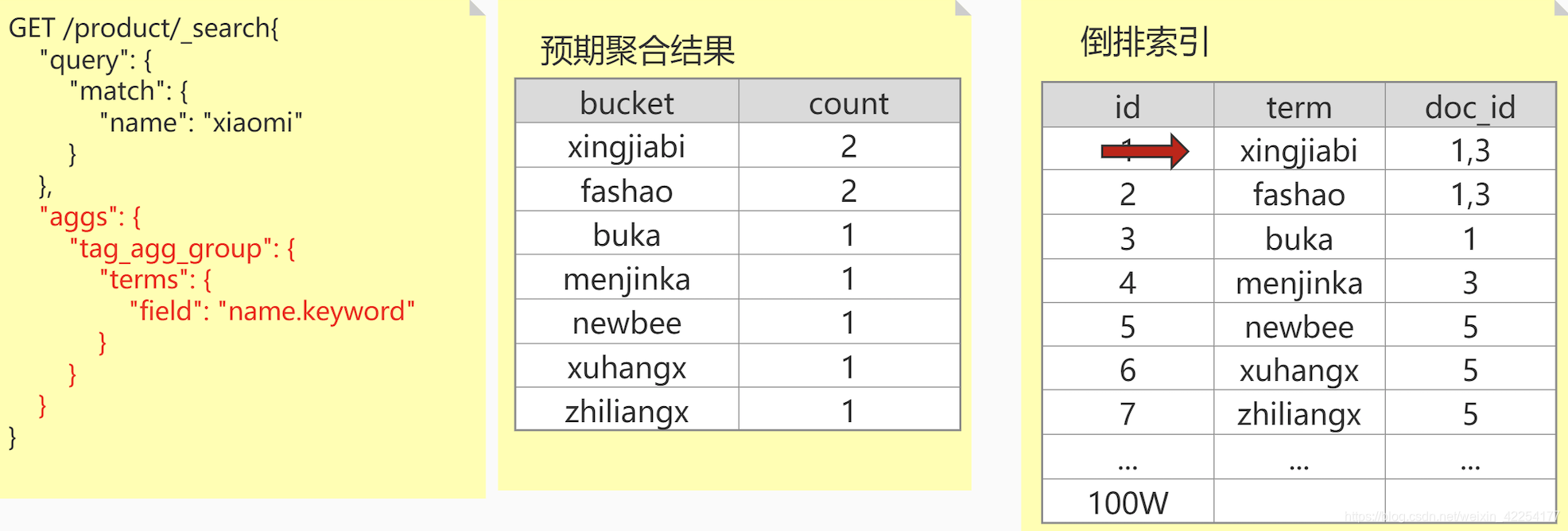
正排索引(doc values )VS 倒排索引:
概念:从广义来说,doc values 本质上是一个序列化的 列式存储 。列式存储 适用于聚合、排序、脚本等操作,所有的数字、地理坐标、日期、IP 和不分析( not_analyzed )字符类型都会默认开启。
特点:倒排索引的优势 在于查找包含某个项的文档,相反,如果用它确定哪些项是否存在单个文档里。
优化:es官方是建议,es大量是基于os cache来进行缓存和提升性能的,不建议用jvm内存来进行缓存,那样会导致一定的gc开销和oom问题,给jvm更少的内存,给os cache更大的内存。比如64g服务器,给jvm最多4~16g(1/16~1/4),os cache可以提升doc value和倒排索引的缓存和查询效率。

正排索引: doc_values VS fielddata
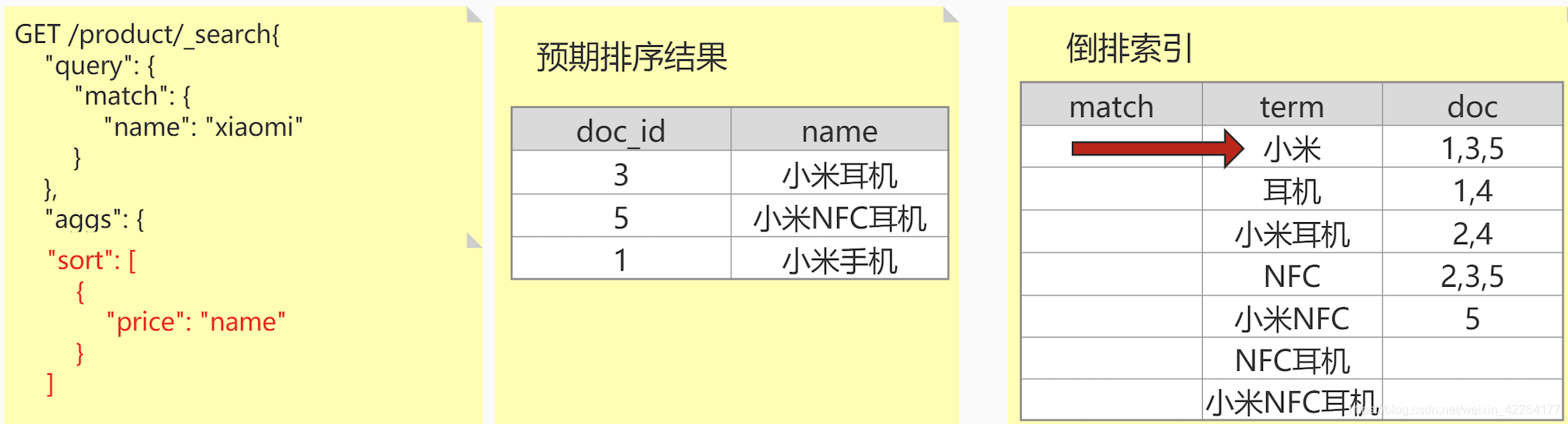
这两个概念源于ES , 除了强大的搜索功能外 , 还可以支持排序,聚合之类的操作
搜索需要用到倒排索引,而排序和聚合则需要使用 “正排索引”。说白了就是一句话,倒排索引的优势在于查找包含某个项的文档,而反过来确定哪些项在单个文档里并不高效。
doc_values和fielddata就是用来给文档建立正排索引的。他俩一个很显著的区别是,前者的工作地盘主要在磁盘,而后者的工作地盘在内存。
我整理了一个表格,从不同维度比较这哥俩。
索引速度稍低这个是相对于fielddata方案的,其实仔细想想也可以理解。那排序举例,相对于一个在磁盘排序,一个在内存排序。谁的速度快自然不用多说。
但是fielddata用的是jvm的内存, 所以默认是关闭的, 不推荐使用, 一般用doc_values就足够了
在ES 1.x版本的官方说法是,
Doc values are now only about 10–25% slower than in-memory fielddata
虽然速度稍慢,doc_values的优势还是非常明显的。一个很显著的点就是他不会随着文档的增多引起OOM问题。正如前面说的,doc_values在磁盘创建排序和聚合所需的正排索引。这样我们就避免了在生产环境给ES设置一个很大的HEAP_SIZE,也使得JVM的GC更加高效,这个又为其它的操作带来了间接的好处。
而且,随着ES版本的升级,对于doc_values的优化越来越好,索引的速度已经很接近fielddata了,而且我们知道硬盘的访问速度也是越来越快(比如SSD)。所以 doc_values 现在可以满足大部分场景,也是ES官方重点维护的对象。
所以我想说的是,doc values相比field data还是有很多优势的。所以 ES2.x 之后,支持聚合的字段属性默认都使用doc_values,而不是fielddata。
基于mget批量查询以及基于bulk的批量增删改
mget:批量查询
跨index: GET /_mget
GET /_mget
{
"docs" : [
{
"_index": "product"
,"_id": 1
},{
"_index": "product"
,"_id": 2
}
]
}同一个index: GET /<index>/_mget
GET /product/_mget
{
"ids" : [1, 2]
}返回的结果都是
{
"docs" : [
{
"_index" : "product",
"_type" : "_doc",
"_id" : "1", // id为1
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "xiaomi phone",
"desc" : "shouji zhong de zhandouji",
"price" : 3999,
"tags" : [
"xingjiabi",
"fashao",
"buka"
]
}
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "2", // id为2
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "xiaomi nfc phone",
"desc" : "zhichi quangongneng nfc,shouji zhong de jianjiji",
"price" : 4999,
"tags" : [
"xingjiabi",
"fashao",
"gongjiaoka"
]
}
}
]
}
include包含哪些字段 exclude排除哪些字段
GET /product/_mget
{
{
"docs":[
{
"_id":2,
"_source":false
},
{
"_id":3,
"_source":[
"name",
"price"
]
},
{
"_id":4,
"_source":{
"include":[
"name"
],
"exclude":[
"price"
]
}
}
]
}
bulk:批量增删改 no-query
语法格式:
POST /_bulk
POST /<index>/_bulk
{"action": {"metadata"}}
{"data"}
POST /_bulk
{ "delete": { "_index": "product2", "_id": "1" }}
{ "create": { "_index": "product2", "_id": "2" }}
{ "name": "_bulk create 2" }
{ "create": { "_index": "product2", "_id": "12" }}
{ "name": "_bulk create 12" }
{ "index": { "_index": "product2", "_id": "3" }}
{ "name": "index product2 " }
{ "index": { "_index": "product2", "_id": "13" }}
{ "name": "index product2" }
{ "update": { "_index": "product2", "_id": "4","retry_on_conflict" : "3"} }
{ "doc" : {"test_field2" : "bulk test1"} }#加?filter_path=items.*.error 只显示失败的
All REST APIs accept a filter_path parameter that can be used to reduce the response returned by Elasticsearch. This parameter takes a comma separated list of filters expressed with the dot notation:
GET /_search?q=kimchy&filter_path=took,hits.hits._id,hits.hits._scoreResponds:
{
"took":3,
"hits":{
"hits":[
{
"_id":"0",
"_score":1.6375021
}
]
}
}
Operate
create:PUT /index/_create/id/,强制创建(如果已经存在, 会报错)(最好指定id, 否则生成的id是字符串形式)
delete:删除(lazy delete原理)
index:可以是创建,也可以是全量替换
update:执行partial update(全量替换,部分替换)
ES并发冲突问题(悲观锁和乐观锁)
悲观锁:各种情况,都加锁,读写锁、行级锁、表级锁。使用简单,但是并发能力很低
乐观锁:并发能力高,操作麻烦,每次no-query操作都需要比对version
ES现在用的是乐观锁, 根据version字段控制
ES写入原理
1. 每次ES写入请求, 都会插入到内存Buffer
2. Refresh操作
Buffer如果被写满了, 或者到了1秒 ( refresh_interval ) 的间隔期限, 会Buffer里的缓存的文档, 写入Segment, 并把Segment同步到OS Cache里
如果出现断电等异常, 那么这部分数据就丢失了. 解决方案是translog文件
同步到OS cache之后, 立即打开Segment, 使原先处于CLOSE状态的Segment, 变成OPEN状态, 客户端的请求就可以打到Segment上了
所以, 数据从写入到可以被搜索, 花了大概1秒多的时间, 所以ES可以被称为NTR近实时搜索.
3. Flush操作
OS Cache的数据量不断的往上涨, 当达到一定阈值, 或者一定时间(默认30分钟), 就会触发flush
将缓存中的Segment全部写入磁盘并确保写入成功, 同时创建一个commit point, 整个过程就是一个完整的commit过程
flush操作步骤:
1. 把Buffer中缓存的文档flush到OS Cache
2. 把OS Cache中缓存的Segment全部fsync到OS Disk
3. 清空translog
fsync到OS Disk, 数据才算落地, 之前的过程中都会有断电丢失数据的可能
图中黄色部分是内存操作, 速度是非常快的
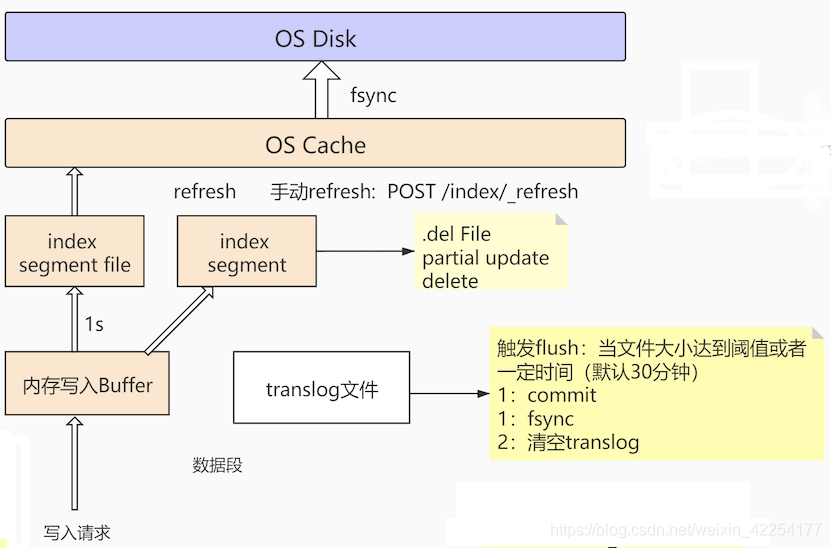
如何解决机器断电的情况下 , OS Cache里的数据丢失的问题?
每进行一次写入Buffer的操作, 都会同时在tranlog文件里记一条日志
当OS Cache同步到OS Disk完成后, 才把对应的tranlog记录清空
每隔1秒, 都会生成一个Segment, 会不会无休止的生成Segment? 解决方案: 合并Segment
1. 选择相似Segment合并
2. flush操作
3. 创建新的commit point标记新的segment, 删除旧的标记
4. 将新的segment搜索状态打开
5. 删除旧的segment文件
commit point
包含了当前可用的Segment
.del文件
被删除的doc不会立马删除, 而是记在.del文件里, 标记删除
更新操作, 也是把原先的记录在.del文件里标记为删除, 然后插入一条新的记录
设置refresh间隔时间
PUT /index
{
"settings": {
"refresh_interval": "2s"
}
}手动执行translog ( 慎用 )
POST /index/_flush