
分片机制通常有两点值得关注:
1. 分片策略
主要有 Hash(哈希)和 Range(范围)两种。你可能还听到过 Key 和 List,其实 Key 和List 可以看作是 Hash 和 Range 的特殊情况,因为机制类似,我们这里就不再细分了。
2. 分片的调度机制
分为静态与动态两种。静态意味着分片在节点上的分布基本是固定的,即使移动也需要人工的介入;动态则是指通过调度管理器基于算法在各节点之间自动地移动分片。
Hash 分片
Hash 分片,就是按照数据记录中指定关键字的 Hash 值将数据记录映射到不同的分片中
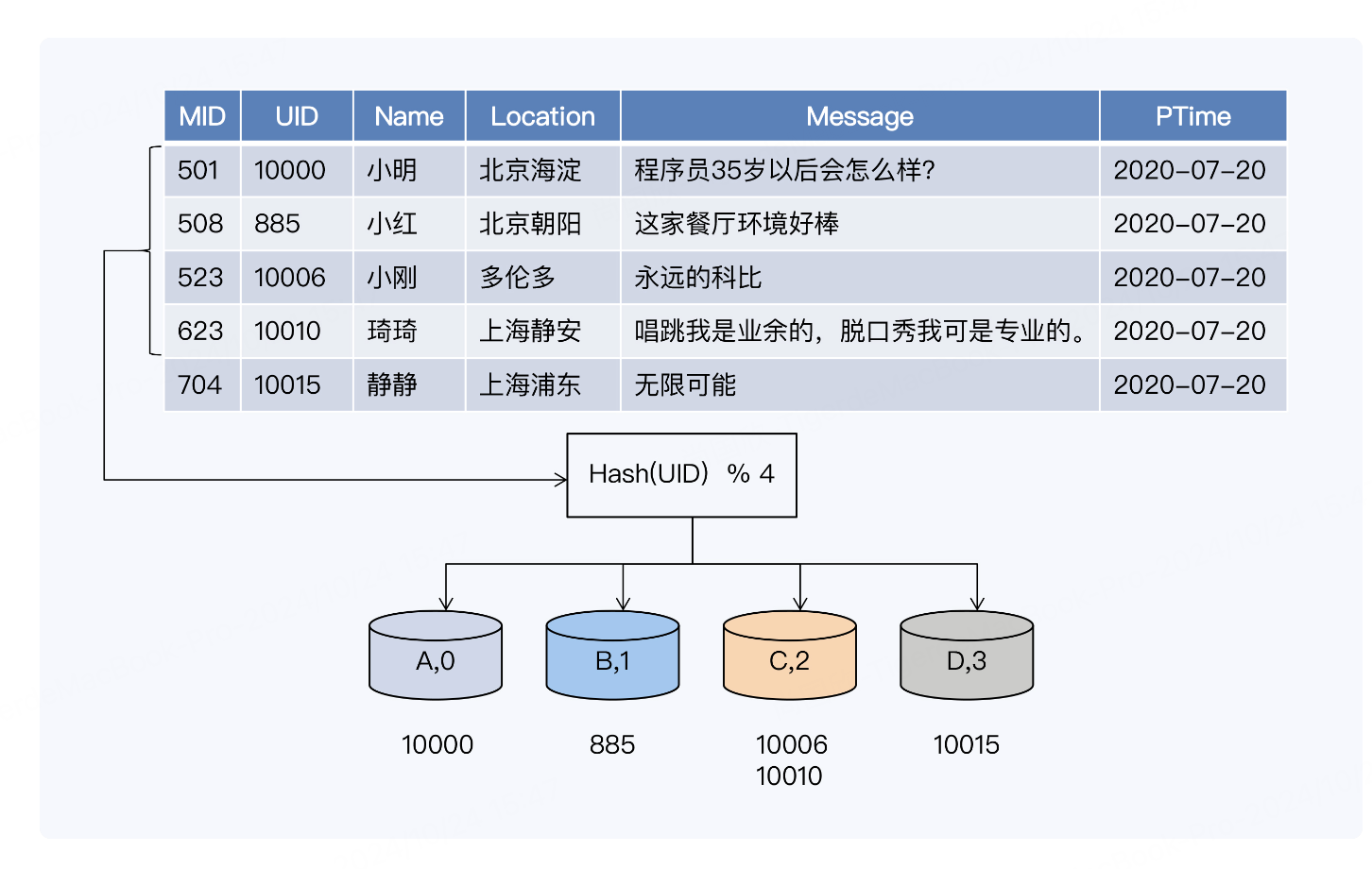
图中的表格部分显示了一个社交网站的记录表,包括主键、用户 ID、分享内容和分享时间
等字段。假设以用户 ID 作为关键字进行分片,系统会通过一个 Hash 函数计算用户 ID 的
Hash 值而后取模,分配到对应的分片。模为 4 的原因是系统一共有四个节点,每个节点
作为一个分片。
因为 Hash 计算会过滤掉数据原有的业务特性,所以可以保证数据非常均匀地分布到多个
分片上,这是 Hash 分片最大的优势,而且它的实现也很简洁。但示例中采用的分片方法
直接用节点数作为模,如果系统节点数量变动,模也随之改变,数据就要重新 Hash 计
算,从而带来大规模的数据迁移。显然,这种方式对于扩展性是非常不友好的。
那接下来的问题就是,我们需要找一个方法提升系统的扩展性。你可能猜到了,这就是一
致性 Hash,该算法首次提出是在论文“Consistent Hashing and Random Trees :
Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web”当
中。2020/8/25
06 | 分片机制:为什么说Range是更好的分片策略?
https://time.geekbang.org/column/article/275696
4/14
要在工业实践中应用一致性 Hash 算法,首先会引入虚拟节点,每个虚拟节点就是一个分
片。为了便于说明,我们在这个案例中将分片数量设定为 16。但实际上,因为分片数量决
定了集群的最大规模,所以它通常会远大于初始集群节点数。
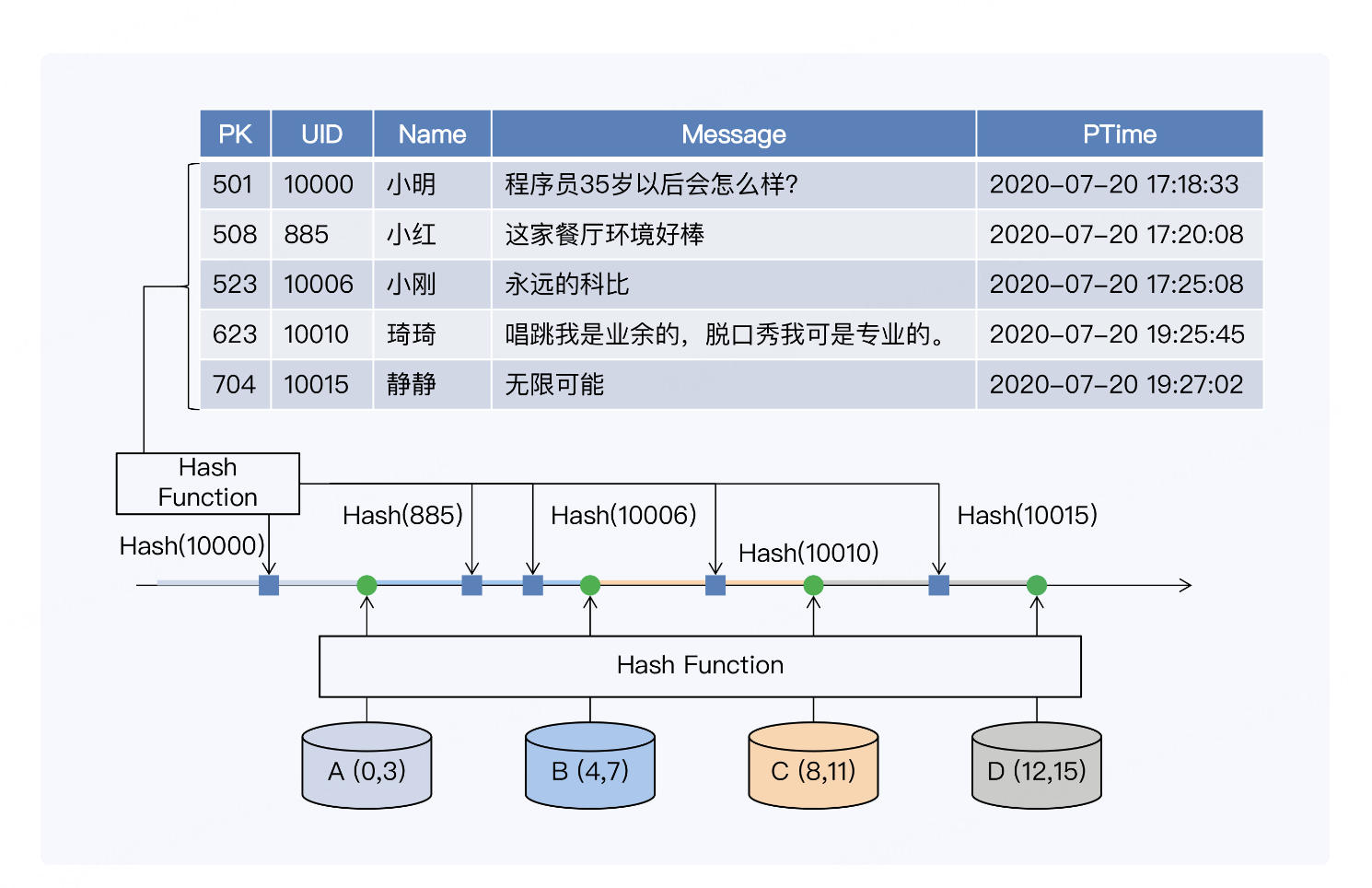
16 个分片构成了整个 Hash 空间,数据记录的主键和节点都要通过 Hash 函数映射到这个
空间。这个 Hash 空间是一个 Hash 环。我们换一种方式画图,可以看得更清楚些。
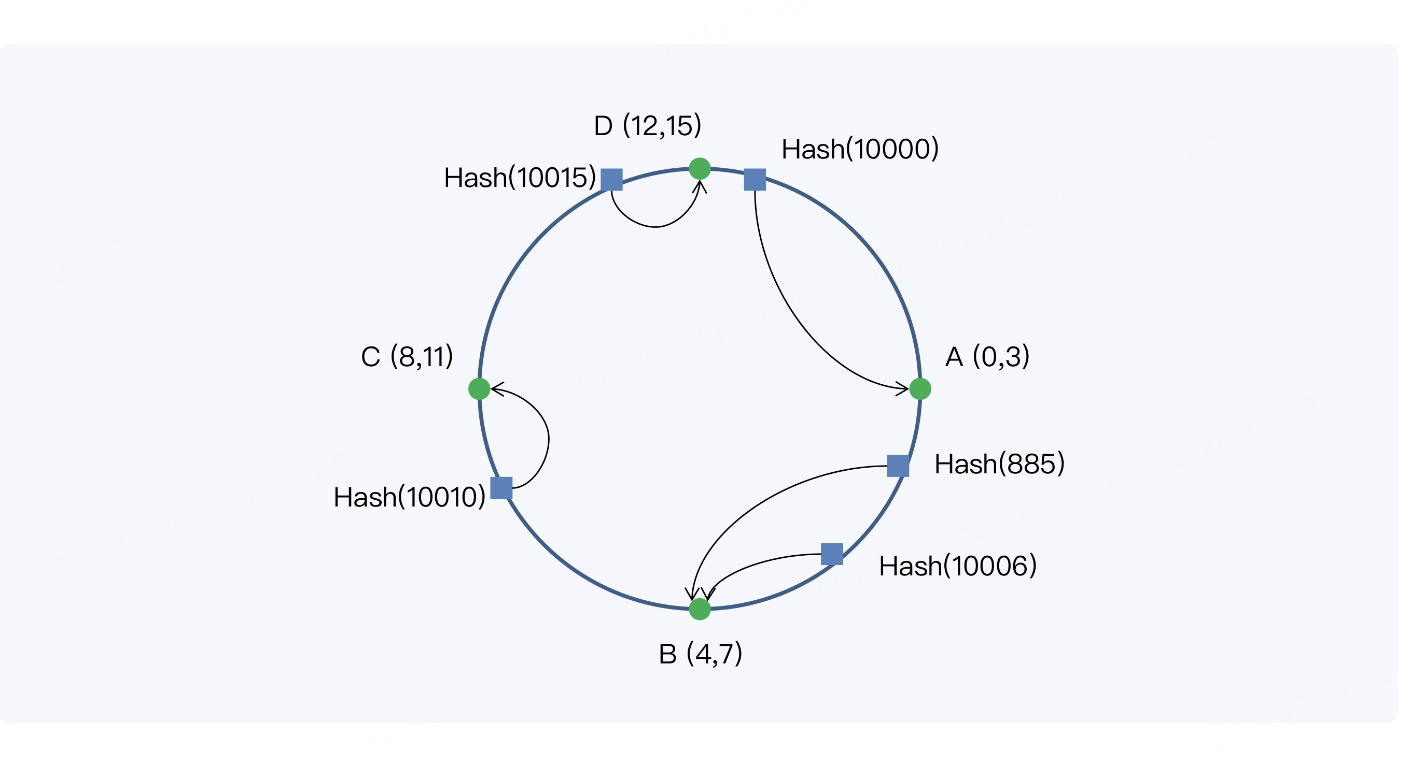
当我们新增一台服务器,即节点 E 时,受影响的数据仅仅是新服务器到其环空间中前一台
服务器(即沿着逆时针方向的第一台服务器)之间数据。结合我们的示例,只有小红分享
的消息从节点 B 被移动到节点 E,其他节点的数据保持不变。此后,节点 B 只存储 Hash
值 6 和 7 的消息,节点 E 存储 Hash 值 4 和 5 的消息。
Hash 函数的优点是数据可以较为均匀地分配到各节点,并发写入性能更好。
本质上,Hash 分片是一种静态分片方式,必须在设计之初约定分片的最大规模。同时,因
为 Hash 函数已经过滤掉了业务属性,也很难解决访问业务热点问题。所谓业务热点,就
是由于局部的业务活跃度较高,形成系统访问上的热点。这种情况普遍存在于各类应用
中,比如电商网站的某个商品卖得比较好,或者外卖网站的某个饭店接单比较多,或者某
个银行网点的客户业务量比较大等等。
Range 静态分片
与 Hash 分片不同,Range 分片的特点恰恰是能够加入对于业务的预估。例如,我们
用“Location”作为关键字进行分片时,不是以统一的行政级别为标准。因为注册地在北
京、上海的用户更多,所以这两个区域可以按照区县设置分片,而海外用户较少,可以按
国家设置为分片。这样,分片间的数据更加平衡。

但是,这种方式依然是静态的,如果海外业务迅速增长,服务海外用户的分片将承担更大
的压力,可能导致性能下降,用户体验不佳。
相对 Hash 分片,Range 分片的适用范围更加广泛。其中一个非常重要的原因是,Range
分片可以更高效地扫描数据记录,而 Hash 分片由于数据被打散,扫描操作的 I/O 开销更
大。Range 静态分片受限于单体数据库的实现机制,很难随数据变动和负载变
化而调整。
Range 动态分片
1. 分片可以自动完成分裂与合并
当单个分片的数据量超过设定值时,分片可以一分为二,这样就可以保证每个分片的数据
量较为均衡。多个数据量较少的分片,会在一定的周期内被合并为一个分片。
分片也会被均衡地调度到各个节点上,节点间的数据量也保持总体平衡。(比如mongoDB)
2. 可以根据访问压力调度分片
我们看到系统之所以尽量维持分片之间,以及节点间的数据量均衡,存储的原因外,还可
以更大概率地将访问压力分散到各个节点上。但是,有少量的数据可能会成为访问热点,
就是上面提到的业务热点,从而打破这种均衡。比如,琦琦和静静都是娱乐明星,有很多
粉丝关注她们分享的内容,其访问量远超过普通人。这时候,系统会根据负载情况,将 R2
和 R3 分别调度到不同的节点,来均衡访问压力。
分片元数据的存储
我们知道,在任何一个分布式存储系统中,收到客户端请求后,承担路由功能的节点首先
要访问分片元数据(简称元数据),确定分片对应的节点,然后才能访问真正的数据。这
里说的元数据,一般会包括分片的数据范围、数据量、读写流量和分片副本处于哪些物理
节点,以及副本状态等信息。
从存储的角度看,元数据也是数据,但特别之处在于每一个请求都要访问它,所以元数据
的存储很容易成为整个系统的性能瓶颈和高可靠性的短板。如果系统支持动态分片,那么
分片要自动地分拆、合并,还会在节点间来回移动。这样,元数据就处在不断变化中,又
带来了多副本一致性(Consensus)的问题。
静态分片
最简单的情况是静态分片。我们可以忽略元数据变动的问题,只要把元数据复制多份放在
对应的工作节点上就可以了,这样同时兼顾了性能和高可靠。TBase 大致就是这个思路,
直接将元数据存储在协调节点上。即使协调节点是工作节点,随着集群规模扩展,会导致
元数据副本过多,但由于哈希分片基本上就是静态分片,也就不用考虑多副本一致性的问
题。
动态分片
但如果要更新分片信息,这种方式显然不适合,因为副本数量过多,数据同步的代价太大
了。所以对于动态分片,通常是不会在有工作负载的节点上存放元数据的。
那要怎么设计呢?有一个凭直觉就能想到的答案,那就是专门给元数据搞一个小规模的集
群,这样保证了高可靠,数据同步的成本也比较低。(比如mongoDB)
TCC
TCC 是 Try、Confirm 和 Cancel 三个单词的缩写,它们是事务过程中的三个操作。
TCC 的整个过程由两类角色参与,一类是事务管理器,只能有一个;另一类是事务参与
者,也就是具体的业务服务,可以是多个,每个服务都要提供 Try、Confirm 和 Cancel 三
个操作。
示例:
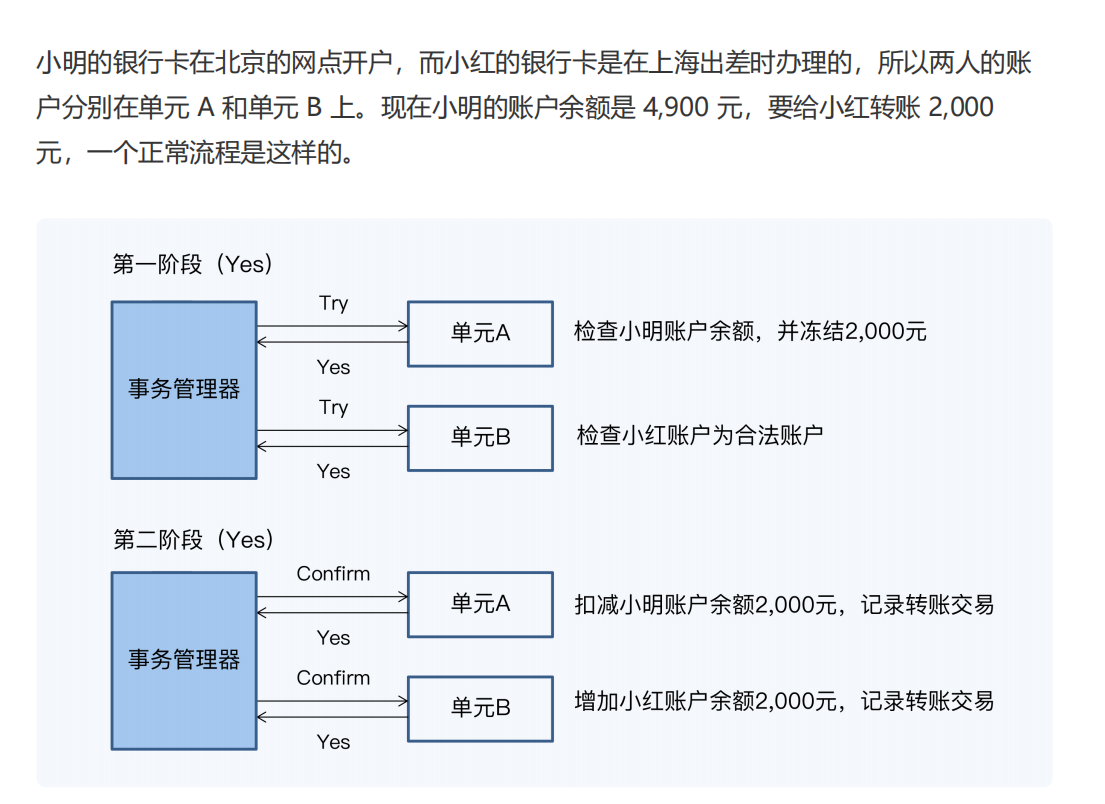
第一阶段,事务管理器会发出 Try 操作,要求进行资源的检查和预留。也就是说,单元 A
要检查小明账户余额并冻结其中的 2,000 元,而单元 B 要确保小红的账户合法,可以接收
转账。在这个阶段,两者账户余额始终不会发生变化。
第二阶段,因为参与者都已经做好准备,所以事务管理器会发出 Confirm 操作,执行真正
的业务,完成 2,000 元的划转。
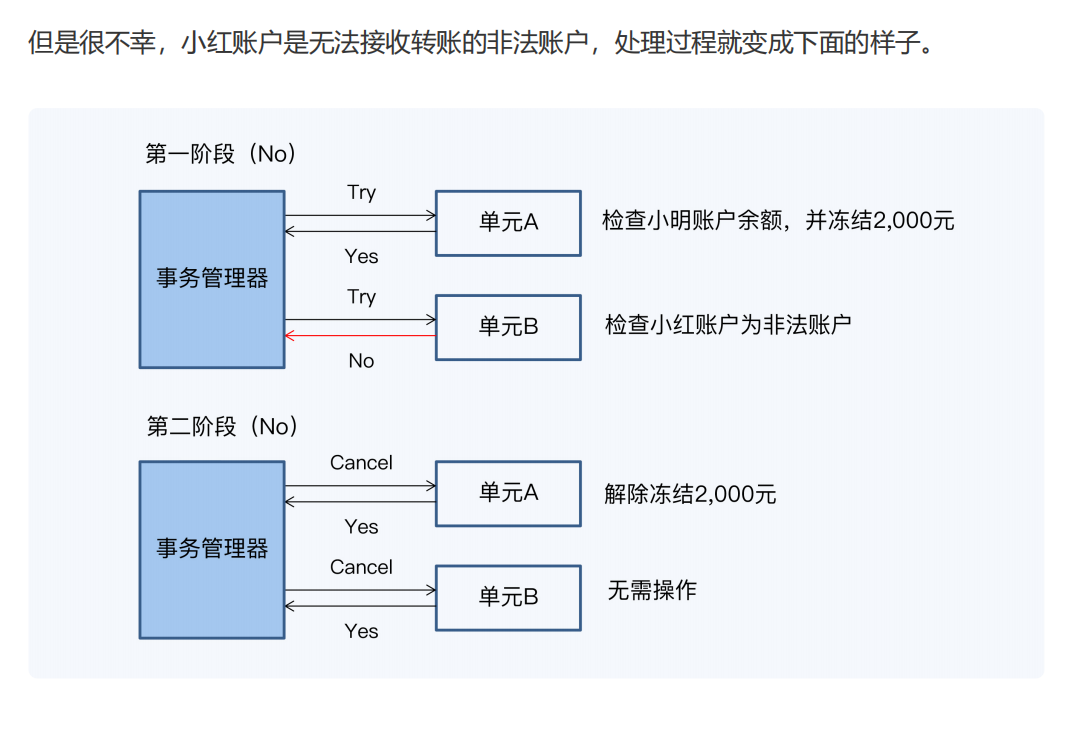
第一阶段,事务管理器发出 Try 指令,单元 B 对小红账户的检查没有通过,回复 No。而
单元 A 检查小明账户余额正常,并冻结了 2,000 元,回复 Yes。
第二阶段,因为前面有参与者回复 No,所以事务管理器向所有参与者发出 Cancel 指令,
让已经成功执行 Try 操作的单元 A 执行 Cancel 操作,撤销在 Try 阶段的操作,也就是单
元 A 解除 2,000 元的资金冻结。
从上述流程可以发现,TCC 仅是应用层的分布式事务框架,具体操作完全依赖于业务编码
实现,可以做针对性的设计,但是这也意味着业务侵入会比较深。
此外,考虑到网络的不可靠,操作指令必须能够被重复执行,这就要求 Try、Confirm、Cancel 必须是幂等性操作,也就是说,要确保执行多次与执行一次得到相同的结果。显然,这又增加了开发难度。(不需要锁数据,AT模式需要对数据行加锁) Cancel是对try进行回滚,因为在保证代码逻辑正确的情况下,Confirm一定会执行成功,除非try资源没锁定完整或者机器出问题,这种情况会重试,超次数后报警。
2PC 的三大问题
相比于 TCC,2PC 的优点是借助了数据库的提交和回滚操作,不侵入业务逻辑。但是,它
也存在一些明显的问题:
1. 同步阻塞
执行过程中,数据库要锁定对应的数据行。如果其他事务刚好也要操作这些数据行,那它
们就只能等待。其实同步阻塞只是设计方式,真正的问题在于这种设计会导致分布式事务
出现高延迟和性能的显著下降。
2. 单点故障
事务管理器非常重要,一旦发生故障,数据库会一直阻塞下去。尤其是在第二阶段发生故
障的话,所有数据库还都处于锁定事务资源的状态中,从而无法继续完成事务操作。
3. 数据不一致
在第二阶段,当事务管理器向参与者发送 Commit 请求之后,发生了局部网络异常,导致
只有部分数据库接收到请求,但是其他数据库未接到请求所以无法提交事务,整个系统就
会出现数据不一致性的现象。比如,小明的余额已经能够扣减,但是小红的余额没有增
加,这样就不符合原子性的要求了。

TCC比如转账try阶段可以通过增加冻结金额字段 先不扣余额,而是冻结资金进行资源预留,避免全局锁。
XA模式



