
doc values
2.1 倒排索引的优势
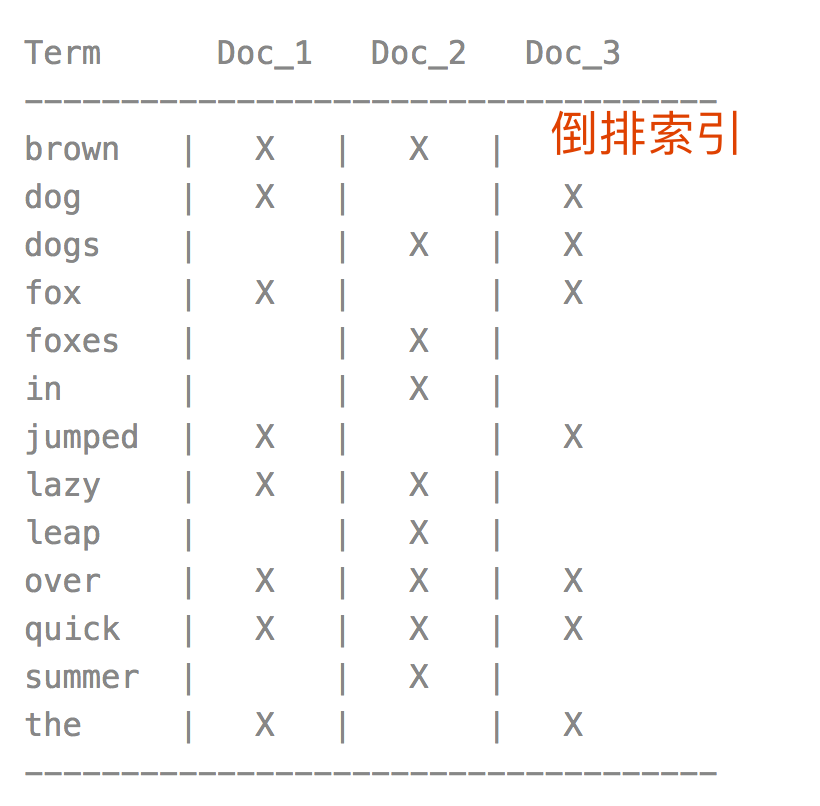
在于查找包含某个项的文档, 搜索使用倒排索引查找文档
2.2 数据结构
doc values使用列式存储,意思是单独存储这个字段列。并且存储的时候会进行压缩,存储后的值是有序的,所以能高效进行排序聚合操作。
2.3 使用场景
Doc values 可以使聚合更快、更高效并且内存友好, 任何需要查找某个文档包含的值的操作都必须使用它。
Doc values 的存在是因为倒排索引只对某些操作是高效的
(1) 聚合操作收集和聚合 doc values 里的数据
(2) 排序
(3) 访问字段值的脚本
(4) 父子关系处理
2.4 写入
Doc Values 是在索引时与 倒排索引 同时生成, 也就是说 Doc Values 和 倒排索引 一样,基于 Segement 生成并且是不可变的
同时 Doc Values 和 倒排索引 一样序列化到磁盘,这样对性能和扩展性有很大帮助
Doc Values 本质上是一个序列化的 列式存储, 列式存储 适用于聚合、排序、脚本等操作
2.5 内存使用
Doc Values 通过序列化把数据结构持久化到磁盘,我们可以充分利用操作系统的内存,而不是 JVM 的 Heap
(1)当 working set 远小于系统的可用内存,系统会自动将 Doc Values 驻留在内存中,使得其读写十分快速
(2)当 working set 远大于可用内存时,系统会根据需要从磁盘读取 Doc Values,然后选择性放到分页缓存中
很显然,这样性能会比在内存中差很多,但是它的大小就不再局限于服务器的内存了。如果是使用 JVM 的 Heap 来实现那么只能是因为 OutOfMemory 导致程序崩溃了。
2.6 禁用
可以通过禁用特定字段的 Doc Values 。这样不仅节省磁盘空间,也许会提升索引的速度
Doc Values 默认对所有字段启用,除了 analyzed strings
也就是下面的数据,都会默认开启
(1) 数字
(2) 地理坐标
(3) 日期
(4) IP
(5) 不分析( not_analyzed )字符类型
因为 Doc Values 默认启用,你可以选择对你数据集里面的大多数字段进行聚合和排序操作
# (1) 创建索引,指定字段 session_id 只能查询(默认index: true),不保存doc values(doc_values: false, 默认值为true)
PUT yz_index
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
# (2) 写入数据
POST yz_index/_doc
{
"session_id": "5f6dcd9221d20b41e16149cca96bfa20"
}
# (3) 查询正常
GET yz_index/_search
# 查询返回
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "yz_index",
"_type" : "_doc",
"_id" : "LQ-tYHcB0oopJCSjEmVl",
"_score" : 1.0,
"_source" : {
"session_id" : "5f6dcd9221d20b41e16149cca96bfa20"
}
}
]
}
}
# (4) 因为没有doc_values, 导致聚合失败
GET yz_index/_search
{
"aggs": {
"NAME": {
"terms": {
"field": "session_id",
"size": 10
}
}
}
}
# 聚合请求的返回值
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [session_id] because fielddata is unsupported on fields of type [keyword]. Use doc values instead."
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "yz_index",
"node" : "Pclb86mySAOhJbGbQ7Rj3g",
"reason" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [session_id] because fielddata is unsupported on fields of type [keyword]. Use doc values instead."
}
}
],
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [session_id] because fielddata is unsupported on fields of type [keyword]. Use doc values instead.",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [session_id] because fielddata is unsupported on fields of type [keyword]. Use doc values instead."
}
}
},
"status" : 400
}
fielddata
3.1 数据结构
doc values 不生成分析的字符串,然而,这些字段仍然可以使用聚合,那怎么可能呢?
答案是一种被称为 fielddata 的数据结构
3.2 存储
与 doc values 不同,
fielddata 构建和管理 100% 在内存中,常驻于 JVM 内存堆;
fielddata 结构不会在索引时创建。相反,它是在查询运行时,动态填充;
这意味着它本质上是不可扩展的,有很多边缘情况下要提防
3.3 高基数内存的影响
(High-Cardinality Memory Implications)
避免分析字段的另外一个原因就是:高基数字段在加载到 fielddata 时会消耗大量内存。
分析的过程会经常(尽管不总是这样)生成大量的 token,这些 token 大多都是唯一的。
这会增加字段的整体基数并且带来更大的内存压力
3.4 查看使用情况
# (1) 创建索引,启用fielddata(默认text类型字段,)
PUT yz_index
{
"settings": {
"number_of_replicas": 0
},
"mappings": {
"properties": {
"f1": {
"type": "text",
"fielddata": true
}
}
}
}
# (2) 查看索引的fielddata 缓存数据,此时刚创建索引,没有查询,所有缓存数据为0
GET yz_index/_stats/fielddata?pretty&human
# 返回值
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_all" : {
"primaries" : {
"fielddata" : {
"memory_size" : "0b",
"memory_size_in_bytes" : 0,
"evictions" : 0
}
},
"total" : {
"fielddata" : {
"memory_size" : "0b",
"memory_size_in_bytes" : 0,
"evictions" : 0
}
}
},
"indices" : {
"yz_index" : {
"uuid" : "fmWv-YKhRG2uAnMBbxQHyg",
"primaries" : {
"fielddata" : {
"memory_size" : "0b",
"memory_size_in_bytes" : 0,
"evictions" : 0
}
},
"total" : {
"fielddata" : {
"memory_size" : "0b",
"memory_size_in_bytes" : 0,
"evictions" : 0
}
}
}
}
}
# (3)添加文档
POST yz_index/_doc
{
"f1": "hello world"
}
POST yz_index/_doc
{
"f1": "hello sunshine"
}
# (4)聚合查询
GET yz_index/_search
{
"size": 0,
"aggs": {
"NAME": {
"terms": {
"field": "f1",
"size": 10
}
}
}
}
# 聚合查询返回值
{
"took" : 604,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"NAME" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "hello",
"doc_count" : 2
},
{
"key" : "sunshine",
"doc_count" : 1
},
{
"key" : "world",
"doc_count" : 1
}
]
}
}
}
# (5)再次查看fielddata内存使用
GET yz_index/_stats/fielddata?pretty&human
# 返回值,因为已经有聚合查询,使用到fielddata,所以fielddata有内存占用
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_all" : {
"primaries" : {
"fielddata" : {
"memory_size" : "520b",
"memory_size_in_bytes" : 520,
"evictions" : 0
}
},
"total" : {
"fielddata" : {
"memory_size" : "520b",
"memory_size_in_bytes" : 520,
"evictions" : 0
}
}
},
"indices" : {
"yz_index" : {
"uuid" : "fmWv-YKhRG2uAnMBbxQHyg",
"primaries" : {
"fielddata" : {
"memory_size" : "520b",
"memory_size_in_bytes" : 520,
"evictions" : 0
}
},
"total" : {
"fielddata" : {
"memory_size" : "520b",
"memory_size_in_bytes" : 520,
"evictions" : 0
}
}
}
}
}
3.5 默认大小与更新
# (1) 查看默认 fielddata 配置
GET _cluster/settings?include_defaults&flat_settings
# 返回值中包含fielddata部分
{
"defaults": {
"indices.breaker.fielddata.limit": "40%",
"indices.breaker.fielddata.overhead": "1.03",
"indices.breaker.fielddata.type": "memory",
"indices.fielddata.cache.size": "-1b"
}
}
(1) indices.fielddata.cache.size
控制为 fielddata 分配的堆空间大小, 默认情况下,设置都是 unbounded ,Elasticsearch 永远都不会从 fielddata 中回收数据
当你发起一个查询,分析字符串的聚合将会被加载到 fielddata,如果这些字符串之前没有被加载过
fielddata 不是临时缓存。它是驻留内存里的数据结构,必须可以快速执行访问,而且构建它的代价十分高昂。如果每个请求都重载数据,性能会十分糟糕
不过如果采用默认设置,旧索引的 fielddata 永远不会从缓存中回收! fieldata 会保持增长直到 fielddata 发生断熔,这样我们就无法载入更多的 fielddata。
为了防止发生这样的事情,可以通过在 config/elasticsearch.yml 文件中增加配置为 fielddata 设置一个上限:
indices.fielddata.cache.size: 20%
注意:无法动态配置 cache size
# 无法动态配置 cache size
PUT /_cluster/settings
{
"persistent" : {
"indices.fielddata.cache.size" : "20%"
}
}
# 返回值
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "persistent setting [indices.fielddata.cache.size], not dynamically updateable"
}
],
"type" : "illegal_argument_exception",
"reason" : "persistent setting [indices.fielddata.cache.size], not dynamically updateable"
},
"status" : 400
}
(2) indices.breaker.fielddata.limit
fielddata 断路器默认设置堆的 40% 作为 fielddata 大小的上限
断路器的限制可以在文件 config/elasticsearch.yml 中指定,可以动态更新一个正在运行的集群:
# 动态配置fielddata熔断器的数值
PUT /_cluster/settings
{
"persistent" : {
"indices.breaker.fielddata.limit" : "41%"
}
}
2、Fielddata
上文说过,在排序、聚合以及在脚本中访问field值时需要一个与倒排索引截然不同的数据访问模式:不同于倒排索引中的查找term->找到对应docs的过程,我们需要直接查找doc然后找到指定某个filed中包含的terms。
大多数field使用索引时、磁盘上的doc_values来支持这种访问模式,但是分词了的String filed不支持Doc Values,而是使用一种叫FieldData的数据结构。
FieldData主要是针对analyzed String,它是一种查询时(query-time)的数据结构。
FieldData缓存主要应用场景是在对某一个field排序或者计算类的聚合运算时。它会把这个field列的所有值加载到内存,这样做的目的是提供对这些值的快速文档访问。为field构建FieldData缓存可能会很昂贵,因此建议有足够的内存来分配它,并保持其处于已加载状态。
FieldData是在第一次将该filed用于聚合,排序或在脚本中访问时按需构建。FieldData是通过从磁盘读取每个段来读取整个反向索引,然后逆置term->doc的关系,并将结果存储在JVM堆中构建的。
所以,加载FieldData是开销很大的操作,一旦它被加载后,就会在整个段的生命周期中保留在内存中。
这了可以注意下FieldData和Doc Values的区别。较早的版本中,其他数据类型也是用的FieldData,但是目前已经用随文档索引时创建的Doc Values所替代。
JVM堆内存资源是非常宝贵的,能用好它对系统的高效稳定运行至关重要。FieldData是直接放在堆内的,所以必须合理设定用于存放它的堆内存资源数。ES中控制FieldData内存使用的参数是indices.fielddata.cache.size,可以用x%表示占该节点堆内存百分比,也可以用如12GB这样的数值。默认状况下,这个设置是无限制的,ES不会从FieldData中驱逐数据。如果生成的fielddata大小超过指定的size,则将驱逐其他值以腾出空间。使用时一定要注意,这个设置只是一个安全策略而并非内存不足的解决方案。因为通过此配置触发数据驱逐,ES会立刻开始从磁盘加载数据,并把其他数据驱逐以保证有足够空间,导致很高的IO以及大量的需要被垃圾回收的内存垃圾。
举个例子来说:每天为日志文件建一个新的索引。一般来说我们只对最近几天数据感兴趣,很少查询老数据。但是,按默认设置FieldData中的老索引数据是不会被驱逐的。这样的话,FieldData就会一直持续增长直到触发熔断机制,这个机制会让你再也不能加载更多的FieldData到内存。这样的场景下,你只能对老的索引访问FieldData,但不能加载更多新数据。所以,这个时候就可以通过以上配置来把最近最少使用的FieldData驱逐以够新进来的数据腾空间。
FieldData是在数据被加载后再检查的,那么如果一个查询导致尝试加载超过可用内存的数据就会导致OOM异常。ES中使用了FieldData Circuit Breaker来处理上述问题,他可以通过分析一个查询涉及到的字段的类型、基数、大小等来评估所需内存。如果估计的查询大小大于配置的堆内存使用百分比限制,则断路器会跳闸,查询将被中止并返回异常。
断路器是工作是在数据加载前,所以你不用担心遇到FieldData导致的OOM异常。ES拥有多种类型的断路器:
indices.breaker.fielddata.limitindices.breaker.request.limitindices.breaker.total.limit
可以根据实际需要进行配置。
FieldData是为分词String而生,它会消耗大量的java 堆空间,特别是加载基数(cardinality)很大的分词String filed时。但是往往对这种类型的分词Field做聚合是没有意义的。
值得注意的是,FieldData和Doc Values的加载时机不同,前者是首次查询时,后者是doc索引时。还有一点,FieldData是按每个段来缓存的。
3、Doc values与Fielddata对比
doc_values与fielddata一个很显著的区别是,前者的工作地盘主要在磁盘,而后者的工作地盘在内存。
索引速度稍低这个是相对于fielddata方案的,其实仔细想想也可以理解。拿排序举例,相对于一个在磁盘排序,一个在内存排序,谁的速度快不言自明。
在ES 1.x版本的官方说法是,
Doc values are now only about 10–25% slower than in-memory fielddata
虽然速度稍慢,doc_values的优势还是非常明显的。一个很显著的点就是它不会随着文档的增多引起OOM问题。正如前面说的,doc_values在磁盘创建排序和聚合所需的正排索引。这样我们就避免了在生产环境给ES设置一个很大的HEAP_SIZE,也使得JVM的GC更加高效,这个又为其它的操作带来了间接的好处。
而且,随着ES版本的升级,对于doc_values的优化越来越好,索引的速度已经很接近fielddata了,而且我们知道硬盘的访问速度也是越来越快(比如SSD)。所以 doc_values 现在可以满足大部分场景,也是ES官方重点维护的对象。
所以我想说的是,doc values相比field data还是有很多优势的。所以 ES2.x 之后,支持聚合的字段属性默认都使用doc_values,而不是fielddata。
4、Global Ordinals 全局序号
Global Ordinals是一个在Doc Values和FieldData之上的数据结构,它为每个唯一的term按字典序维护了一个自增的数字序列。每个term都有自己的一个唯一数字,而且字母A的全局序号小于字母B。特别注意,全局序号只支持String类型的field。
请注意,Doc Values和FieldData也有自己的ordinals序号,这个序号是特定segment和field中的唯一编号。通过提供Segment Ordinals和Global Ordinals间的映射关系,全局序号只是在此基础上创建,后者(即全局序号)是在整个shard分片中是唯一的。
一个特定字段的Global Ordinals跟一个分片中的所有段相关,而Doc Values和FieldData的ordinals只跟单个段相关。因此,只要是一个新段要变得可见,那么就必须完全重建全局序号。
也就是说,跟FieldData一样,在默认情况下全局序号也是懒加载的,会在第一个请求FieldData命中一个索引时来构建全局序号。实际上,在为每个段加载FieldData后,ES就会创建一个称为Global Ordinals(全局序号)的数据结构来构建一个由分片内的所有段中的唯一term组成的列表。
全局序号的内存开销小的原因是它由非常高效的压缩机制。提前加载的全局序号可以将加载时间从第一次搜索时转到全局序号刷新时。
全局序号的加载时间依赖于一个字段中的term数量,但是总的来说耗时较低,因为来源的字段数据都已经加载到内存了。
全局序号在用到段序号的时候很有用,比如排序或者terms aggregation,可以提升执行效率。
我们举个简单的例子。比如有十亿级别的doc,每个doc都有一个status字段,但只有pending, published, deleted三个状态数据。如果直接存整个String数据到内存,那么就算每个doc有15字节,那么一共就是差不多14GB的数据。怎么减少占用空间呢?首先想到的就是用数字来进行编码,码表如下:
Ordinal | Term
-------------------
0 | status_deleted
1 | status_pending
2 | status_published
这样的话,初始的那三个String就只在码表内被存了一次。FieldData中的doc就可以直接用编码来指向实际值:
Doc | Ordinal
-------------------------
0 | 1 # pending
1 | 1 # pending
2 | 2 # published
3 | 0 # deleted
这样编码以后,直接把数据量压缩了十倍左右。但有个问题是FieldData是按每个段来分别加载、缓存的。那么就会出现一个情况,如果一个段内的doc只有deleted和published两个状态,那么就会导致该FieldData算出来的码表只有0和1,这就和拥有3个状态的段算出的FieldData码表不同。这样的话,聚合的时候就必须一个段一个段的计算,最后再聚合,十分缓慢,开销巨大。
ES的做法是用Global Ordinals这种构建在FieldData之上的小巧数据结构,编码会结合所有段来计算唯一值然后存放为一个序号码表。这样一来,term aggregation可以只在全局序号上进行聚合,而且只会在聚合的最终阶段来计算从序号到真实的String值一次。这个机制可以提升聚合的性能3-4倍。
Roaring Bitmaps (for filter cache)
在 ES 中,可以使用 filters 来优化查询,filter 查询只处理文档是否匹配与否,不涉及文档评分操作,查询的结果可以被缓存。
对于 filter 查询,es 提供了 filter cache 这种特殊的缓存,filter cache 用来存储 filters 得到的结果集。缓存 filters 不需要太多的内存,它只保留一种信息,即哪些文档与 filter 相匹配。同时它可以由其它的查询复用,极大地提升了查询的性能。
联合查询
如果查询有 filter cache,那就是直接拿 filter cache 来做计算,也就是说位图来做 AND 或者 OR 的计算。
如果查询的 filter 没有缓存,那么就用 skip list 的方式去遍历磁盘上的 postings list。