
我们在使用Redis分片集群时,集群最好的状态就是每个实例可以处理相同或相近比例的请求,但如果不是这样,则会出现某些实例压力特别大,而某些实例特别空闲的情况发生,本文就一起来看下这种情况是如何发生的以及如何处理。
1:什么是数据倾斜
数据倾斜分为两种,第一种是数据量倾斜,第二种是数据访问倾斜,定义如下:
数据量倾斜:数据分布的不均匀,导致某些实例数据特别多,进而导致处理的请求量大
数据访问倾斜:数据分布均匀,但是某些实例存在热点数据,进而导致处理的请求量大
可以看到不管是数据量倾斜,还是数据访问倾斜,最终导致的结果都是发生倾斜的实例处理了更多的数据请求,压力增大。
2:数据量倾斜
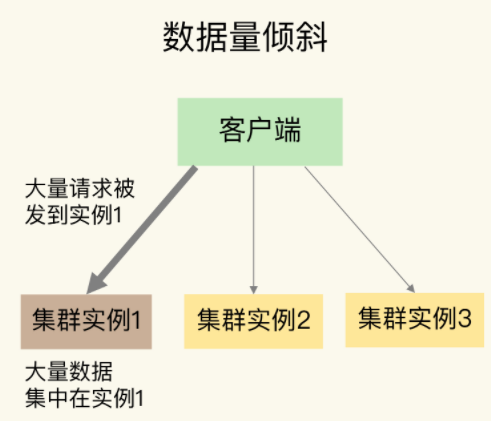
数据量倾斜最常见的原因就是在手动划分slot时,分配不均匀,除此之外,还有big key,hash tag,分别来看下。
2.1:slot分配不均匀
slot分配不均匀一般是由于手动分配造成,或者是因为某个实例节点配置较高,为了更加充分的利用其计算机资源,有意的给其分配更多的slot,但是这个多出的量其实是不好预估的,所以对于因为计算机性能差异有意分配的造成的slot不均匀还是要尽量避免,即保证所有的实例节点都具有相同的配置,然后将slot进行均匀分配。如果是已经发生了slot分配不均匀,我们可以通过迁移slot的方式来处理,首先通过cluster slots命令查看当前slot的分配情况:
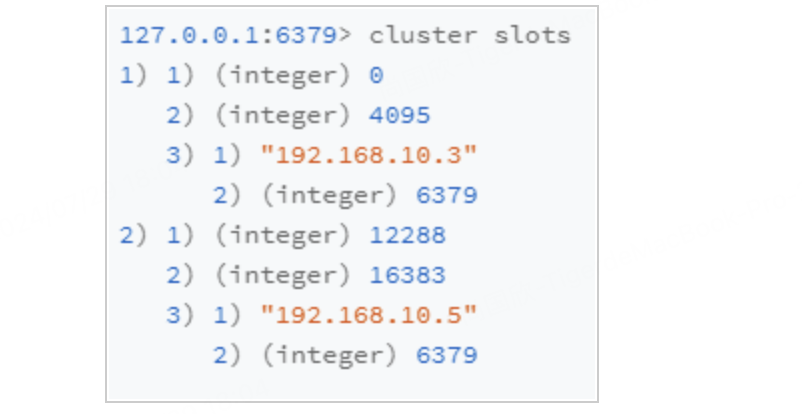
上图slot0~4095分配到了实例192.168.10.3:6379,slot12288~16383分配到了实例192.168.10.5:6379。如下是一个slot迁移的例子。
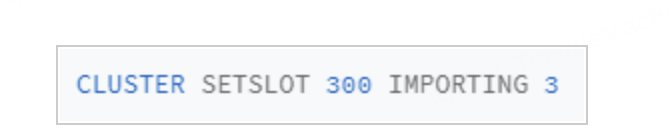
假设我们要把 Slot 300 从源实例(ID 为 3)迁移到目标实例(ID 为 5),那要怎么做呢?
第1步,我们先在目标实例5上执行下面的命令,将Slot 300的源实例设置为实例 3,表示要从实例 3 上迁入 Slot 300。
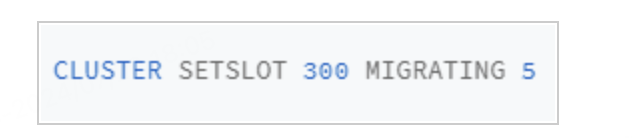
第2步,在源实例 3 上,我们把 Slot 300 的目标实例设置为 5,这表示,Slot 300 要迁出到实例 5 上,如下所示:
第3步,从 Slot 300 中获取 100 个 key。因为 Slot 中的 key 数量可能很多,所以我们需要在客户端上多次执行下面的这条命令,分批次获得并迁移 key。

第4步,我们把刚才获取的 100 个 key 中的 key1 迁移到目标实例 5 上(IP 为 192.168.10.5),同时把要迁入的数据库设置为 0 号数据库,把迁移的超时时间设置为 timeout。我们重复执行 MIGRATE 命令,把 100 个 key 都迁移完。

最后,我们重复执行第 3 和第 4 步,直到 Slot 中的所有 key 都迁移完成。
从Redis3.0.6开始,你也可以使用KEYS选项,一次迁移多个key(key1、2、3),这样可以提升迁移效率。

2.2:big key
bigkey,主要包括string的值特别大,和集合类型的元素特别多两种情况,对于string,我们需要在业务上处理,分散到多个key存储,然后在业务上多次获取,并进行合并,比如如下划分:
其实这里是用到了分片的思想,对于集合的处理方式和string也是类似的,比如有一个包含100万个元素的hash集合user:info,分片存储后如下:
对于bigkey我们还是要在业务上尽量避免,因为bigkey的副作用不仅仅如此,还有如数据同步慢,数据恢复慢,删除慢等。
2.3:hash tag
我们正常设置key,计算其slot值的方式是crc16(key)%16384,但是如果是使用了{},比如keypart1:{keypart2},则计算的逻辑就变成了crc16(keypart2)%16384,一般用在希望某几类key分布到同一个实例,进而可以方便的进行某些操作的场景,如事务,简单的计算等,但是一般带来的的负面影响要比收益大的多,比如造成这里分析的数据倾斜问题,数据倾斜影响的是整个Redis实例,影响更大,所以在实践中要尽量避免使用hash tag。
3:数据访问倾斜
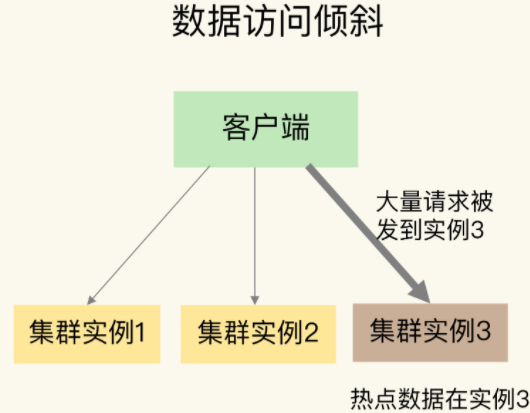
数据访问倾斜出现的场景一般就是热点数据,比如首页的新闻,某明星出轨离婚等爆点新闻,对于这类问题一般有如下的解决方法:
1:拷贝几份数据,以分散到不同的实例
比如news:1,可以虚拟出几份数据,如news:1:A,news:1:B,...news:1:Z,客户端访问时随机的增加A~Z的后缀,分散压力,这种方法可以用于只读的热点数据
2:增加机器配置
这种方法是针对读写数据,因为如果是按照方案1,数据的一致性将会带来额外的性能开销,以及更多潜在的bug。
怎么把一部分槽迁移到另一部分
在 Redis Cluster 中,可以使用 CLUSTER 命令来将槽(slots)从一个节点迁移到另一个节点。具体步骤如下:
1. 确认目标节点
首先,确认当前集群的节点信息及其分配的槽。
sh复制代码
redis-cli -c -p <port> CLUSTER NODES
2. 将槽设置为导入和导出模式
在源节点上将需要迁移的槽设置为导出模式:
sh复制代码
redis-cli -c -p <source_node_port> CLUSTER SETSLOT <slot_number> IMPORTING <target_node_id>
在目标节点上将需要迁移的槽设置为导入模式:
sh复制代码
redis-cli -c -p <target_node_port> CLUSTER SETSLOT <slot_number> MIGRATING <source_node_id>
3. 迁移数据
使用 redis-cli 的 migrate 命令将数据从一个节点迁移到另一个节点:
sh复制代码
redis-cli -c -p <source_node_port> CLUSTER GETKEYSINSLOT <slot_number> <count>
这会返回指定槽中的键,然后你可以使用 migrate 命令将这些键迁移到目标节点:
sh复制代码
redis-cli -c -p <source_node_port> MIGRATE <target_node_ip> <target_node_port> "" 0 <timeout> KEYS <key1> <key2> ...
4. 更新槽分配
完成数据迁移后,更新槽分配信息:
在源节点上将槽设置为空:
sh复制代码
redis-cli -c -p <source_node_port> CLUSTER SETSLOT <slot_number> NODE <target_node_id>
在目标节点上确认槽分配:
sh复制代码
redis-cli -c -p <target_node_port> CLUSTER SETSLOT <slot_number> NODE <target_node_id>
5. 重新平衡集群
完成槽迁移后,你可能需要重新平衡集群,以确保负载均衡。可以使用 Redis 集群管理工具如 redis-trib 或 redis-cli 的 CLUSTER 命令来进行自动化重新平衡。
以上步骤可以帮助你将 Redis Cluster 中的槽从一个节点迁移到另一个节点,从而调整集群的负载和性能。
读流量倾斜处理
1、复制多份副本
我们可以在key的后面拼上有序编号,比如key#01、key#02。。。key#10多个副本,这些加工后的key位于多个缓存节点上。
客户端每次访问时,只需要在原key的基础上拼接一个分片数上限的随机数,将请求路由不到的实例节点。
注意:缓存一般都会设置过期时间,为了避免缓存的集中失效,我们对缓存的过期时间尽量不要一样,可以在预设的基础上增加一个随机数。
至于数据路由的均匀性,这个由 Hash 算法来保证
2、本地内存缓存
把热点数据缓存在客户端的本地内存中,并且设置一个失效时间。对于每次读请求,将首先检查该数据是否存在于本地缓存中,如果存在则直接返回,如果不存在再去访问分布式缓存的服务器。
好思路
本地内存缓存彻底“解放”了缓存服务器,不会对缓存服务器有任何压力。
缺点:实时感知最新的缓存数据有点麻烦,会产生数据不一致的情况。我们可以设置一个比较短的过期时间,采用被动更新。当然,也可以用监控机制,如果感知到数据已经发生了变化,及时更新本地缓存。
个人理解还有办法就是给热点key打tag然后放到同一个节点上,增加该节点的从节点数量均衡读流量。