
计数
假如要存储帖子维度(帖子的计数,转发数、赞数等等)的数据,你可以这么设计表结构:以帖子 ID 为主键,转发数、评论数、点赞数和浏览数分别为单独一列,这样在获取计数时用一个 SQL 语句就搞定了。
select repost_count, comment_count, praise_count, view_count from t_weibo_count where tweet_id = ?
在数据量级和访问量级都不大的情况下,这种方式最简单,所以如果你的系统量级不大,你可以直接采用这种方式来实现。
MySQL 数据库单表的存储量级达到几千万的时候,性能上就会有损耗。所以我们考虑使用分库分表的方式分散数据量,提升读取计数的性能。
如果计数的访问量会多很多量级,
仅仅靠数据库已经完全不能承担如此高的并发量了。于是我们考虑使用 Redis 来加速读请求,通过部署多个从节点来提升可用性和性能,并且通过 Hash 的方式对数据做分片,也基本上可以保证计数的读取性能。然而,这种数据库 + 缓存的方式有一个弊端:无法保证数据的一致性,比如,如果数据库写入成功而缓存更新失败,就会导致数据的不一致,影响计数的准确性。所以,我们完全抛弃了 MySQL,全面使用 Redis 来作为计数的存储组件。
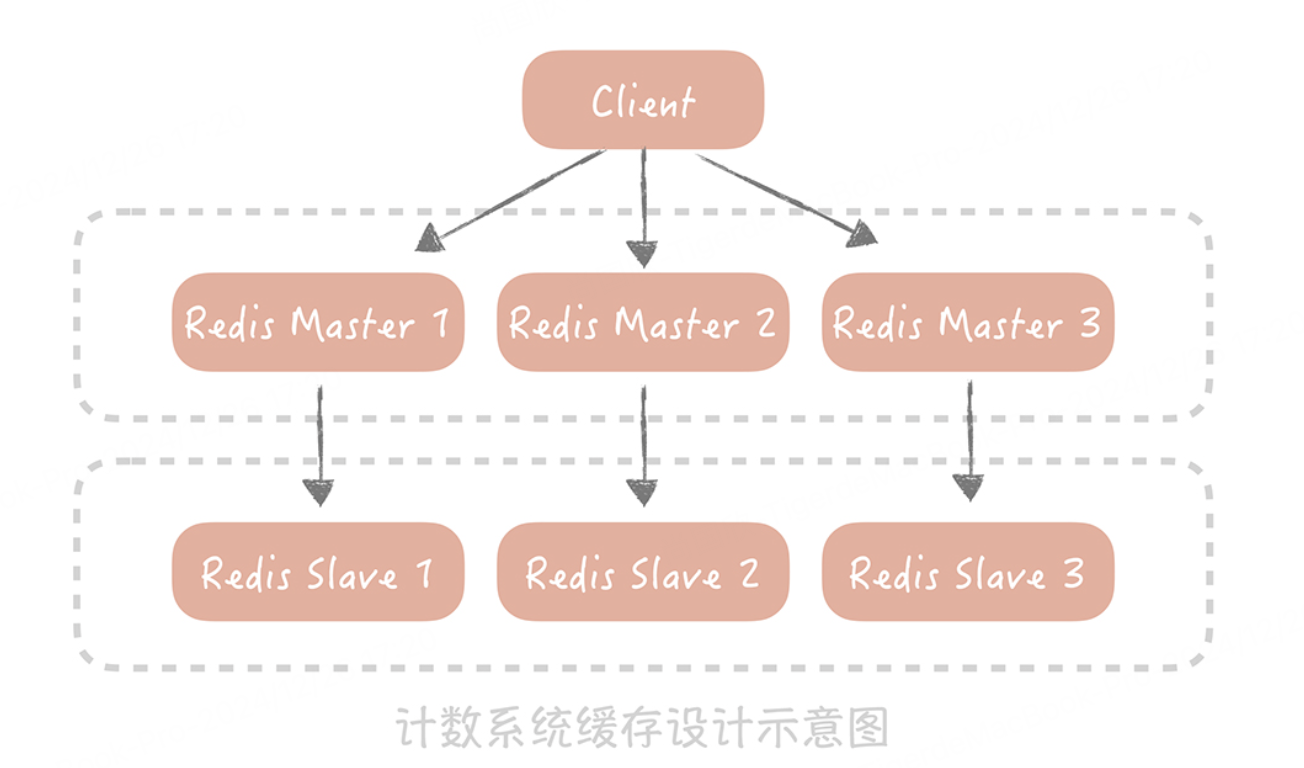
除了考虑计数的读取性能之外,由于热门帖子的计数变化频率相当快,也需要考虑如何提升计数的写入性能。比如,每次在转发一条帖子的时候,都需要增加这条帖子的转发数,那么如果比较热门的帖子,瞬时就可能会产生几万甚至几十万的转发。
我们可以用消息队列来削峰填谷了,也就是说,我们在转发帖子的时候向消息队列写入一条消息,然后在消息处理程序中给这条帖子的转发计数加 1。这里需要注意的一点, 我们可以通过批量处理消息的方式进一步减小 Redis 的写压力。比方批量消费消息,可以合并多条计数转为一次,比如转发3次需要3次IO,可以合并一次+3的操作。
如何降低计数系统的存储成本
帖子的计数有转发数、评论数、浏览数、点赞数等等,如果每一个计数都需要存储 tweet_id,那么总共就需要 8(tweet_id)*4(4 个帖子 ID)+4(转发数) + 4(评论数) + 4(点赞数) + 4(浏览数)= 48 字节。但是我们可以把相同帖子 ID 的计数存储在一起,这样就只需要记录一个帖子 ID,省掉了多余的三个微博 ID 的存储开销,存储空间就进一步减少了。
冷热分离
帖子计数的数据具有明显的热点属性:越是最近的帖子越是会被访问到,时间上久远的帖子被访问的几率很小。所以为了尽量减少服务器的使用,我们考虑给计数服务增加 SSD 磁盘,然后将时间上比较久远的数据 dump 到磁盘上,内存中只保留最近的数据。当我们要读取冷数据的时候,使用单独的 I/O 线程异步地将冷数据从 SSD 磁盘中加载到一块儿单独的 Cold Cache 中。
系统通知的未读数要如何设计
假如有3个用户关注了某个用户,那么当这个用户发帖子的时候就需要遍历他的3个粉丝,让未读数+1,或者给所有用户发送系统通知,如果是一个很火的用户有亿级粉丝,成本就很高。
首先,获取全量用户就是一个比较耗时的操作,相当于对用户库做一次全表的扫描,这不仅会对数据库造成很大的压力,而且查询全量用户数据的响应时间是很长的,对于在线业务来说是难以接受的。
假如你的系统中有一个亿的用户,给一个用户增加未读数需要消耗 1ms,那么给所有人都增加未读计数就需要 100000000 * 1 /1000 = 100000 秒,也就是超过一天的时间;即使你启动 100 个线程并发的设置,也需要十几分钟的时间才能完成,而用户很难接受这么长的延迟时间。
另外,使用这种方式需要给系统中的每一个用户都记一个未读数的值,而在系统中,活跃用户只是很少的一部分,大部分的用户是不活跃的,甚至从来没有打开过系统通知,为这些用户记录未读数显然是一种浪费。
可以记录一下在这个列表中每个人看过最后一条消息的 ID,然后统计这个 ID 之后有多少条消息,这就是未读数了。
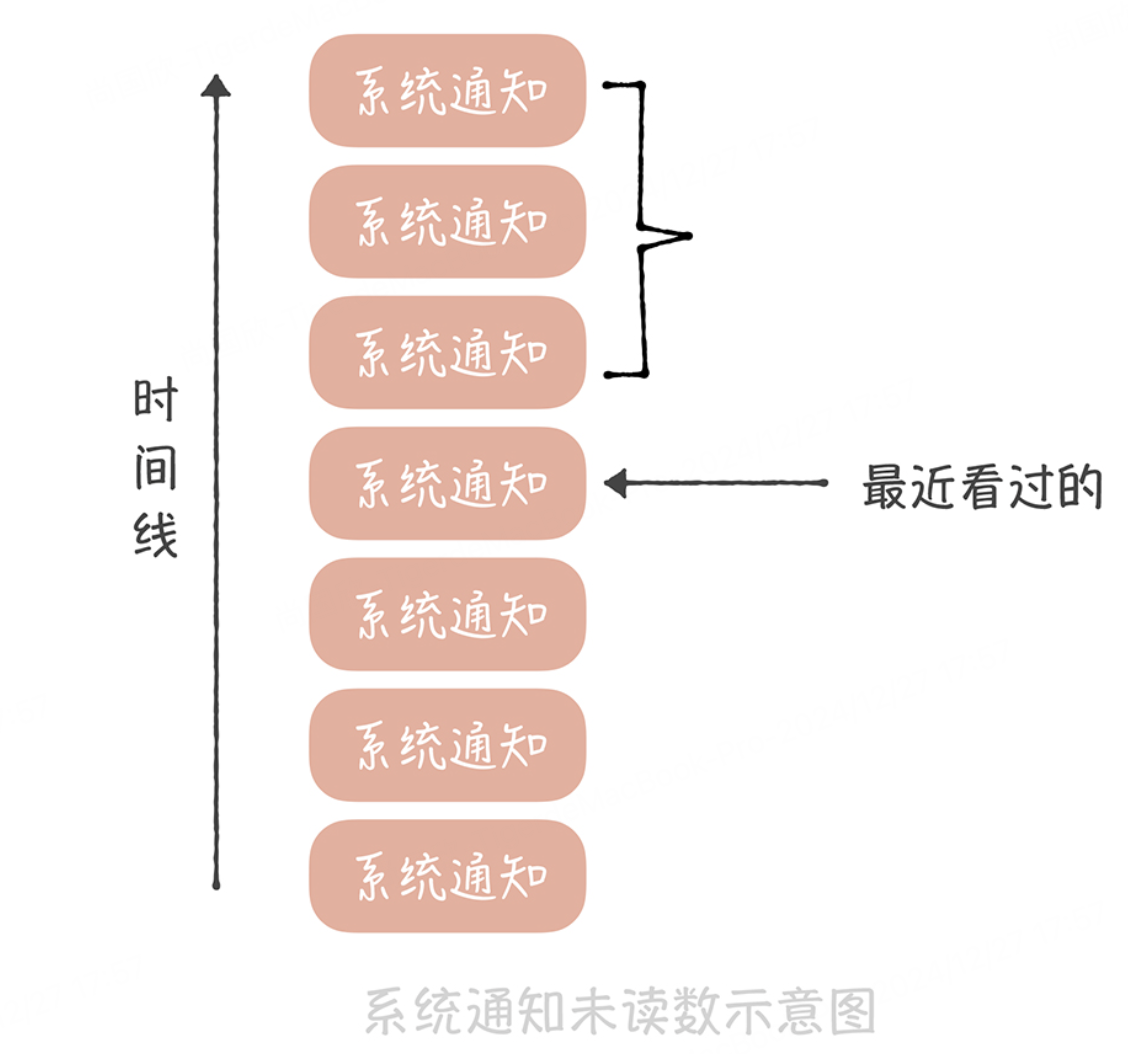
这个方案在实现时有这样几个关键点:
用户访问系统通知页面需要设置未读数为 0,我们需要将用户最近看过的通知 ID 设置为最新的一条系统通知 ID;
如果最近看过的通知 ID 为空,则认为是一个新的用户,返回未读数为 0;
对于非活跃用户,比如最近一个月都没有登录和使用过系统的用户,可以把用户最近看过的通知 ID 清空,节省内存空间。
这是一种比较通用的方案,即节省内存,又能尽量减少获取未读数的延迟。 这个方案适用的另一个业务场景是全量用户打点的场景,比如社区的小红点。
这个红点和系统通知类似,也是一种通知全量用户的手段,如果逐个通知用户,延迟也是无法接受的。因此你可以采用和系统通知类似的方案。
通用信息流要如何设计
一般会有三种方案:推;拉;结合。
推:
比如一个大V用户有千万或者上亿粉丝,如果使用推的方式,每发布一个帖子就需要存到发件箱里,同时还要为每个用户的收件箱写一份数据,那么发一个帖子就可能产生上亿的数据,对于存储成本是很高的。
这种方式的优势是查询相对简单,用户只需要查询自己收件箱的内容就可以,理论上一个sql就能完成。缺点:可能存储成本很高,并且发一个帖子,写收件箱可能需要很久才能完成,资源消耗大。
拉:
基于拉的模式,用户发帖只需写发件箱,不存在收件箱的概念,普通用户浏览的时候需要聚合各个关注人的数据,对于查询的成本消耗较大。比如一个人关注了2000个用户,那每次查询就需要聚合2000个用户数据。性能很低。
基于这种情况可以把用户的发贴存到缓存比如Redis里多个节点上,比如6个节点,那么查6次就能聚合出结果,
性能可以保证 。
缺点:如果存储全部帖子,成本会很高,可以分析用户一般只会流量最近几天的内容,所以只保存最近几天内容即可,优化存储。
如果关注了150个用户,每个帖子id是8字节,那么可能就需要返回1kb的数据,假如每秒10w的用户请求,那么带宽就要每秒100mb,基本就打满了,所以针对这种情况可以在多个节点存储副本,将流量分散,假如总共副本4个,平均每个带宽可以降到 25mb/s,至于本地缓存,用户发帖较多可能会占用大量堆空间,影响正常逻辑处理,需要结合实际情况考虑。
结合:
还有一种是两者结合,对于大V用户我们使用拉的方式,小V使用推的模式,整体会更合理,比如可以设定粉丝数多少是大V,其次,对于推数据,我们可以只推给活跃用户,能够减小很大的写成本 ,但是需要维护活跃用户列表。
比如一个用户在发帖或者流量或者点赞等之后变成活跃用户,就需要把他加到所关注用户的活跃列表里,活跃列表是一个定长的结构,如果满了就需要把最先添加的(或者最近最久未使用的)删掉 。