
监控指标如何选择
在服务层面一般需要监控四个指标,分别是延迟,通信量、错误和饱和度。
延迟指的是请求的响应时间。比如,接口的响应时间、访问数据库和缓存的响应时间。
通信量可以理解为吞吐量,也就是单位时间内,请求量的大小。比如,访问第三方服务的请求量,访问消息队列的请求量。
错误表示当前系统发生的错误数量。这里需要注意的是, 我们需要监控的错误既有显示的,比如在监控 Web 服务时,出现 4 * * 和 5 * * 的响应码;也有隐示的,比如,Web 服务虽然返回的响应码是 200,但是却发生了一些和业务相关的错误(出现了数组越界的异常或者空指针异常等),这些都是错误的范畴。
饱和度指的是服务或者资源到达上限的程度(也可以说是服务或者资源的利用率),比如说 CPU 的使用率,内存使用率,磁盘使用率,缓存数据库的连接数等等。
如何采集数据指标
一般使用 Java 语言开发的中间件,或者组件,都可以通过 JMX 获取统计或者监控信息。比如 可以使用 JMX,监控 Kafka 队列的堆积数,再比如,你也可以通过 JMX 监控 JVM 内存信息和 GC 相关的信息。
另一种很重要的数据获取方式,是在代码中埋点。
最后,日志也是你监控数据的重要来源之一。
监控数据的处理和存储
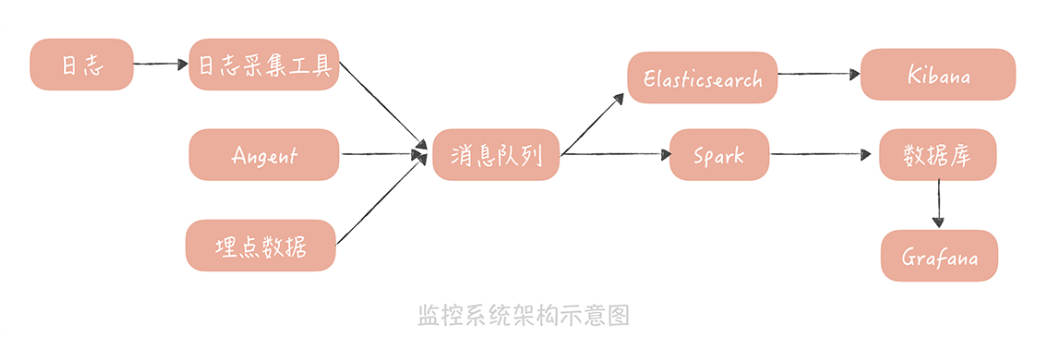
在采集到监控数据之后,你就可以对它们进行处理和存储了,在此之前,我们一般会先用消息队列来承接数据,主要的作用是削峰填谷,防止写入过多的监控数据,让监控服务产生影响。
与此同时,我们一般会部署两个队列处理程序,来消费消息队列中的数据。
一个处理程序接收到数据后,把数据写入到 Elasticsearch,然后通过 Kibana 展示数据,这份数据主要是用来做原始数据的查询;
另一个处理程序是一些流式处理的中间件,比如,Spark、Storm。它们从消息队列里,接收数据后会做一些处理,这些处理包括:
- **解析数据格式,尤其是日志格式。**从里面提取诸如请求量、响应时间、请求 URL 等数据;
- 对数据做一些聚合运算。 比如,针对 Tomcat 访问日志,可以计算同一个 URL 一段时间之内的请求量、响应时间分位值、非 200 请求量的大小等等。
- **将数据存储在时间序列数据库中。**这类数据库的特点是,可以对带有时间标签的数据,做更有效的存储,而我们的监控数据恰恰带有时间标签,并且按照时间递增,非常适合存储在时间序列数据库中。目前业界比较常用的时序数据库有 InfluxDB、OpenTSDB、Graphite,各大厂的选择均有不同,你可以选择一种熟悉的来使用。
- 最后, 就可以通过 Grafana 来连接时序数据库,将监控数据绘制成报表。
配置中心
为了加快产品的研发速度,大概率不会注意配置管理的问题,会自然而然地把配置项和代码写在一起。但是随着配置项越来越多,为了更好地对配置项进行管理,同时避免修改配置项后还要对代码做重新的编译,你选择把配置项独立成单独的文件(文件可以是 properties 格式、xml 格式或 yaml 格式)。不过,这些文件还是会和工程一起打包部署,只是更改配置后不需要对代码重新编译了。
虽然把配置拆分了出来,但是由于配置还是和代码打包在一起,如果要更改一个配置,还是需要重新打包,这样无疑会增加打包的时间。于是,你考虑把配置写到单独的目录中,这样,修改配置就不需要再重新打包了(不过,由于配置并不能够实时地生效,所以想让配置生效,还是需要重启服务)。
并且多个服务有的配置是一样的,有的是不同的,如果每个服务都配置,维护成本很高。
配置中心可以算是微服务架构中的一个标配组件了。业界也提供了多种开源方案供你选择,比较出名的有携程开源的 Apollo,百度开源的 Disconf,360 开源的 QConf,Spring Cloud 的组件 Spring Cloud Config 等等。
在我看来,Apollo 支持不同环境,不同集群的配置,有完善的管理功能,支持灰度发布、更改热发布等功能,在所有配置中心中功能比较齐全。
配置信息如何存储
其实,配置中心和注册中心非常类似,其核心的功能就是对于配置项的存储和读取。所以,在设计配置中心的服务端时,我们需要选择合适的存储组件,来存储大量的配置信息,这里可选择的组件有很多。
事实上,不同的开源配置中心也使用了不同的组件,比如 Disconf、Apollo 使用的是 MySQL;QConf 使用的是 ZooKeeper。我之前维护和使用的配置中心就会使用不同的存储组件,比如微博的配置中心使用 Redis 来存储信息,而美图的则使用 Etcd。
变更推送如何实现
配置信息存储之后,我们需要考虑如何将配置的变更推送给服务端,这样就可以实现配置的动态变更,不需要重启服务器就能让配置生效了。而我们一般会有两种思路来实现变更推送:一种是轮询查询的方式;一种是长连推送的方式。
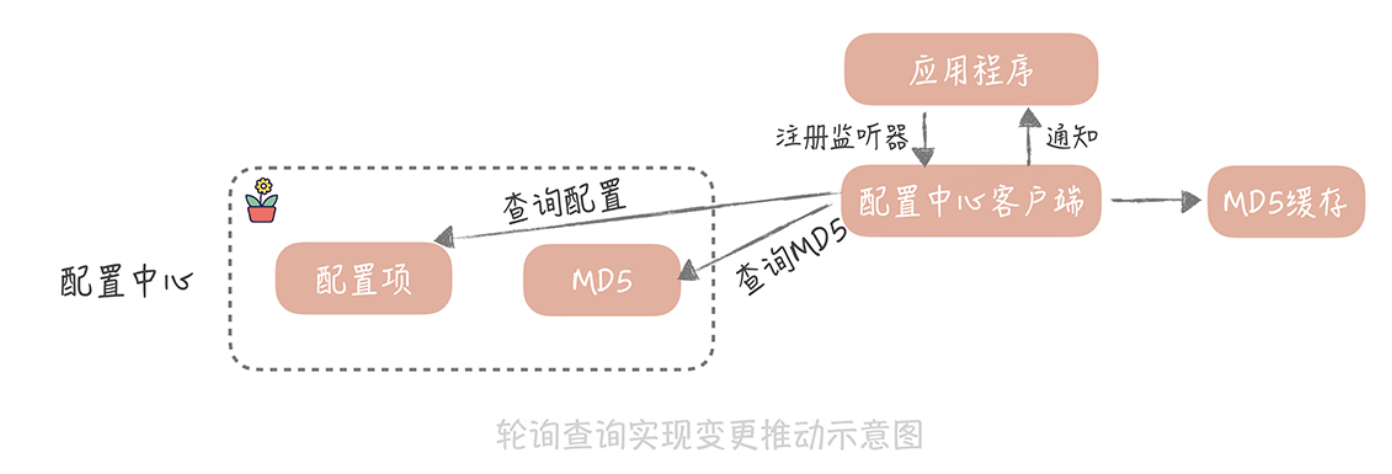
轮询查询很简单,就是应用程序向配置中心客户端注册一个监听器,配置中心的客户端,定期地(比如 1 分钟)查询所需要的配置是否有变化,如果有变化则通知触发监听器,让应用程序得到变更通知。
这里有一个需要注意的点,如果有很多应用服务器都去轮询拉取配置,由于返回的配置项可能会很大,那么配置中心服务的带宽就会成为瓶颈。为了解决这个问题,我们会给配置中心的每一个配置项,多存储一个根据配置项计算出来的 MD5 值。
配置项一旦变化,这个 MD5 值也会随之改变。配置中心客户端在获取到配置的同时,也会获取到配置的 MD5 值,并且存储起来。那么在轮询查询的时候,需要先确认存储的 MD5 值,和配置中心的 MD5 是不是一致的。如果不一致,这就说明配置中心中,存储的配置项有变化,然后才会从配置中心拉取最新的配置。
由于配置中心里存储的配置项变化的几率不大,所以使用这种方式后,每次轮询请求就只是返回一个 MD5 值,可以大大地减少配置中心服务器的带宽。
另一种长连的方式,则是在配置中心服务端保存每个连接关注的配置项列表。这样,当配置中心感知到配置变化后,就可以通过这个连接,把变更的配置推送给客户端。这种方式需要保持长连,也需要保存连接和配置的对应关系,实现上要比轮询的方式复杂一些,但是相比轮询方式来说,能够更加实时地获取配置变更的消息。
而在我看来,配置服务中存储的配置变更频率不高,所以对于实时性要求不高,但是期望实现上能够足够简单,所以如果选择自研配置中心的话,可以考虑使用轮询的方式。
Apollo使用长轮询处理,配置中心 Config Service 会维护每个客户端的长轮询请求,当有新的配置发布时,它会立即返回响应通知客户端更新。如果没有更新,连接会在超时时间(默认 60 秒)后返回并重新发起请求。
如何保证配置中心高可用
除了变更通知以外,在配置中心实现中,另外一个比较关键的点在于如何保证它的可用性,因为对于配置中心来说,它的可用性的重要程度要远远大于性能。这是因为我们一般会在服务器启动时,从配置中心中获取配置,如果配置获取的性能不高,那么外在的表现也只是应用启动时间慢了,对于业务的影响不大;但是,如果获取不到配置,很可能会导致启动失败。
比如,我们把数据库的地址存储在了配置中心里,如果配置中心宕机导致我们无法获取数据库的地址,那么自然应用程序就会启动失败。因此,我们的诉求是让配置中心“旁路化”。也就是说,即使配置中心宕机,或者配置中心依赖的存储宕机,我们仍然能够保证应用程序是可以启动的。
我们一般会在配置中心的客户端上,增加两级缓存:第一级缓存是内存的缓存;另外一级缓存是文件的缓存。
配置中心客户端在获取到配置信息后,会同时把配置信息同步地写入到内存缓存,并且异步地写入到文件缓存中。内存缓存的作用是降低客户端和配置中心的交互频率,提升配置获取的性能;而文件的缓存的作用就是灾备,当应用程序重启时,一旦配置中心发生故障,那么应用程序就会优先使用文件中的配置,这样虽然无法得到配置的变更消息(因为配置中心已经宕机了),但是应用程序还是可以启动起来的,算是一种降级的方案。
熔断降级
首先,我们来看看熔断机制的实现方式。这个机制参考的是电路中保险丝的保护机制,当电路超负荷运转的时候,保险丝会断开电路,保证整体电路不受损害。而服务治理中的熔断机制指的是在发起服务调用的时候,如果返回错误或者超时的次数超过一定阈值,则后续的请求不再发向远程服务而是暂时返回错误。
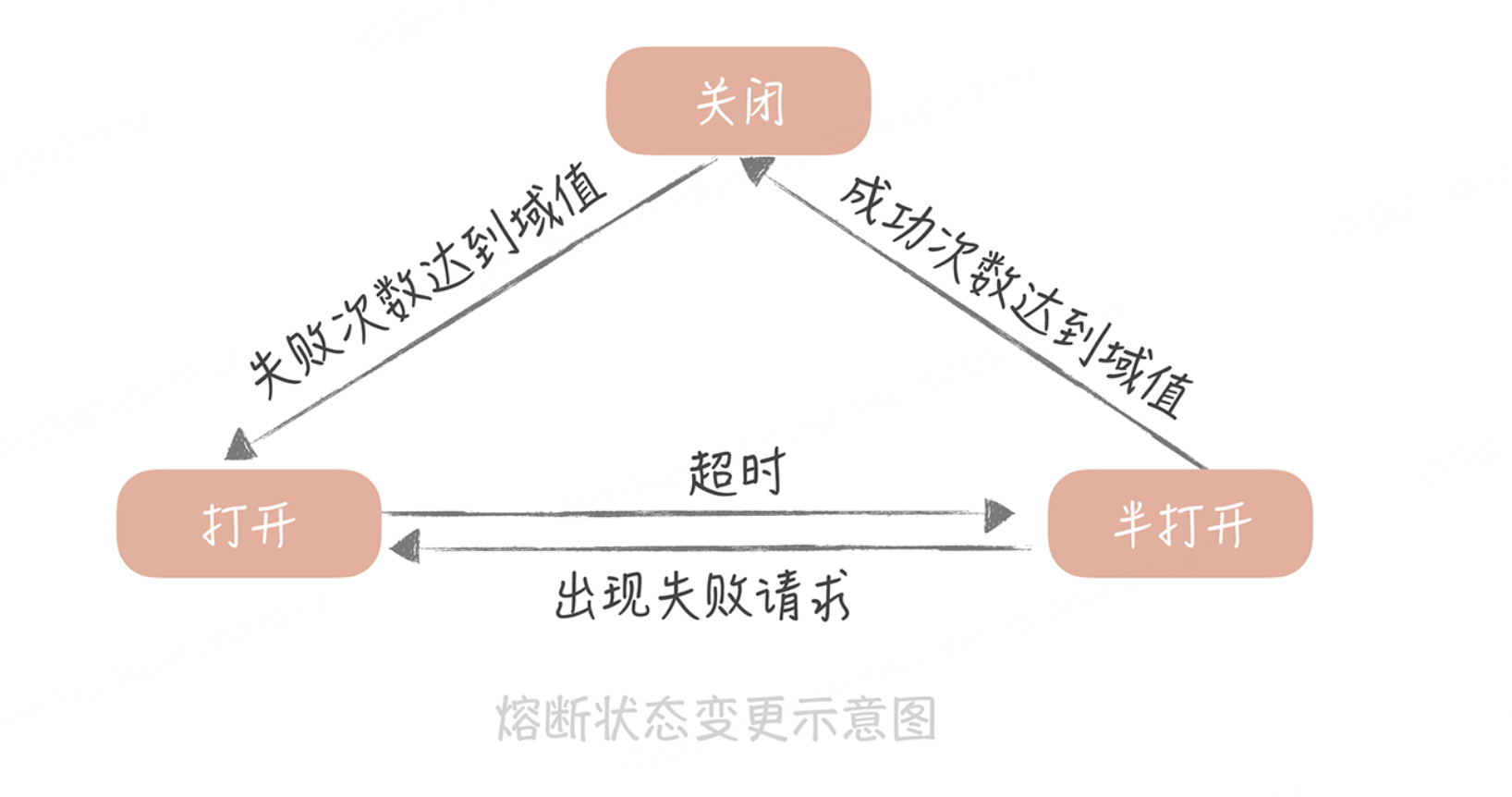
这种实现方式在云计算领域又称为断路器模式,在这种模式下,服务调用方为每一个调用的服务维护一个有限状态机,在这个状态机中会有三种状态:关闭(调用远程服务)、半打开(尝试调用远程服务)和打开(返回错误)。
当调用失败的次数累积到一定的阈值时,熔断状态从关闭态切换到打开态。一般在实现时,如果调用成功一次,就会重置调用失败次数。
当熔断处于打开状态时,我们会启动一个超时计时器,当计时器超时后,状态切换到半打开态。你也可以通过设置一个定时器,定期地探测服务是否恢复。
在熔断处于半打开状态时,请求可以达到后端服务,如果累计一定的成功次数后,状态切换到关闭态;如果出现调用失败的情况,则切换到打开态。
模拟调用redis实现熔断操作:
new Timer("RedisPort-Recover", true).scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
if (breaker.isOpen()) {
Jedis jedis = null;
try {
jedis = connPool.getResource();
jedis.ping(); // 验证 redis 是否可用
successCount.set(0); // 重置连续成功的计数
breaker.setHalfOpen(); // 设置为半打开态
} catch (Exception ignored) {
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}
}, 0, recoverInterval); // 初始化定时器定期检测 redis 是否可用
if (breaker.isOpen()) {
return null; // 断路器打开则直接返回空值
}
K value = null;
Jedis jedis = null;
try {
jedis = connPool.getResource();
value = callback.call(jedis);
if(breaker.isHalfOpen()) { // 如果是半打开状态
if(successCount.incrementAndGet() >= SUCCESS_THRESHOLD) {// 成功次数超过阈值
failCount.set(0); // 清空失败数
breaker.setClose(); // 设置为关闭态
}
}
return value;
} catch (JedisException je) {
if(breaker.isClose()){ // 如果是关闭态
if(failCount.incrementAndGet() >= FAILS_THRESHOLD){ // 失败次数超过阈值
breaker.setOpen(); // 设置为打开态
}
} else if(breaker.isHalfOpen()) { // 如果是半打开态
breaker.setOpen(); // 直接设置为打开态
}
throw je;
} finally {
if (jedis != null) {
jedis.close();
}
}
相比熔断来说,降级是一个更大的概念。因为它是站在整体系统负载的角度上,放弃部分非核心功能或者服务,保证整体的可用性的方法,是一种有损的系统容错方式。这样看来,熔断也是降级的一种,除此之外还有限流降级、开关降级等等。
开关降级指的是在代码中预先埋设一些“开关”,用来控制服务调用的返回值。比方说,开关关闭的时候正常调用远程服务,开关打开时则执行降级的策略。这些开关的值可以存储在配置中心中,当系统出现问题需要降级时,只需要通过配置中心动态更改开关的值,就可以实现不重启服务快速地降级远程服务了。
boolean switcherValue = getFromConfigCenter("degrade.comment"); // 从配置中心获取开关的值
if (!switcherValue) {
List<Comment> comments = getCommentList(); // 开关关闭则获取评论数据
} else {
List<Comment> comments = new ArrayList(); // 开关打开,则直接返回空评论数据
}
我们在设计开关降级预案的时候,首先要区分哪些是核心服务,哪些是非核心服务。因为我们只能针对非核心服务来做降级处理,然后就可以针对具体的业务,制定不同的降级策略了。
针对读取数据的场景,我们一般采用的策略是直接返回降级数据。比如,如果数据库的压力比较大,我们在降级的时候,可以考虑只读取缓存的数据,而不再读取数据库中的数据;如果非核心接口出现问题,可以直接返回服务繁忙或者返回固定的降级数据。
对于一些轮询查询数据的场景,比如每隔 30 秒轮询获取未读数,可以降低获取数据的频率(将获取频率下降到 10 分钟一次)。
而对于写数据的场景,一般会考虑把同步写转换成异步写,这样可以牺牲一些数据一致性和实效性来保证系统的可用性。
限流
系统的峰值流量会超过了预估的峰值,对于核心服务也产生了比较大的影响,这时候不能把核心服务整体降级,
限流需要注意的地方:
限流算法选择不当,导致限流效果不好;
开启了限流却发现整体性能有损耗;
只实现了单机的限流却没有实现整体系统的限流。
限流指的是通过限制到达系统的并发请求数量,保证系统能够正常响应部分用户请求,而对于超过限制的流量,则只能通过拒绝服务的方式保证整体系统的可用性。限流策略一般部署在服务的入口层,比如 API 网关中,这样可以对系统整体流量做塑形。而在微服务架构中,也可以在 RPC 客户端中引入限流的策略,来保证单个服务不会被过大的流量压垮。
限流算法
固定窗口与滑动窗口的算法
固定窗口算法(临界点问题):
private AtomicInteger counter;
ScheduledExecutorService timer = Executors.newSingleThreadScheduledExecutor();
timer.scheduleAtFixedRate(new Runnable(){
@Override
public void run() {
counter.set(0);
}
}, 0, 1, TimeUnit.SECONDS);
public boolena isRateLimit() {
return counter.incrementAndGet() >= allowedLimit;
}
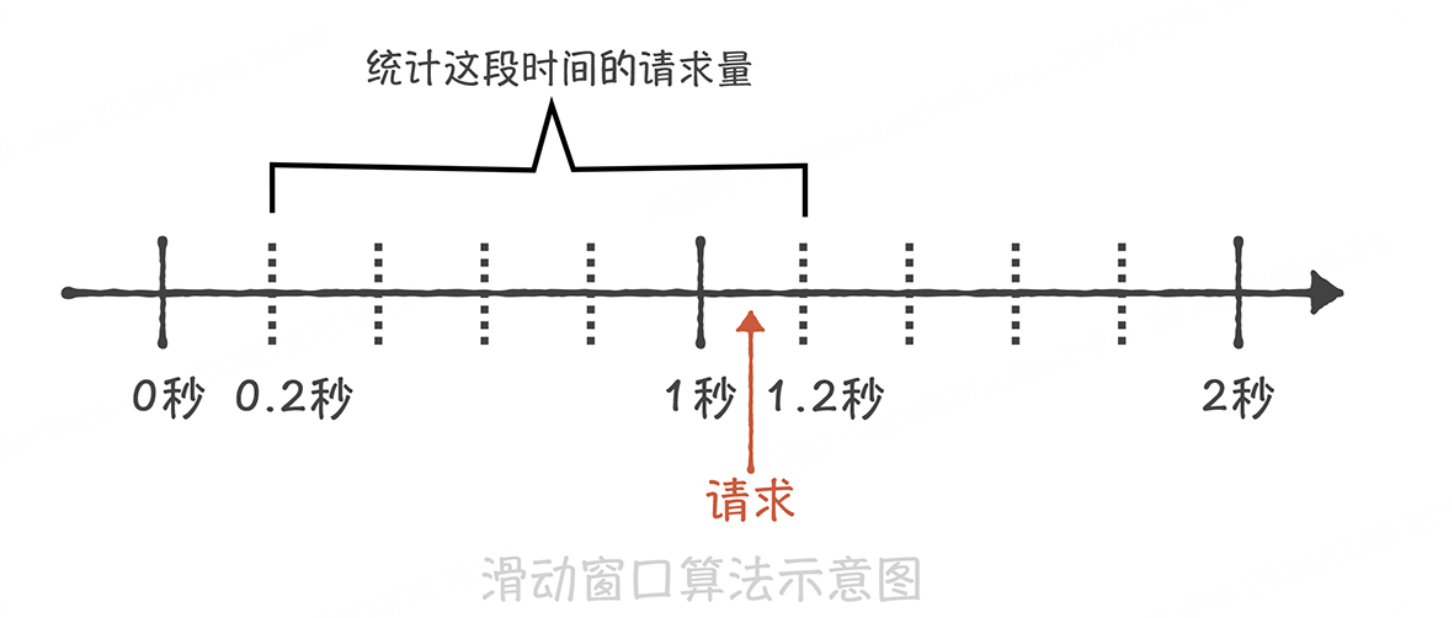
滑动窗口算法:
这个算法的原理是将时间的窗口划分为多个小窗口,每个小窗口中都有单独的请求计数。比如我们将 1s 的时间窗口划分为 5 份,每一份就是 200ms;那么当在 1s 和 1.2s 之间来了一次新的请求时,我们就需要统计之前的一秒钟内的请求量,也就是 0.2s~1.2s 这个区间的总请求量,如果请求量超过了限流阈值那么就执行限流策略。
滑动窗口的算法解决了临界时间点上突发流量无法控制的问题,但是却因为要存储每个小的时间窗口内的计数,所以空间复杂度有所增加。
虽然滑动窗口算法解决了窗口边界的大流量的问题,但是它和固定窗口算法一样,还是无法限制短时间之内的集中流量,也就是说无法控制流量让它们更加平滑。
漏桶算法与令牌筒算法
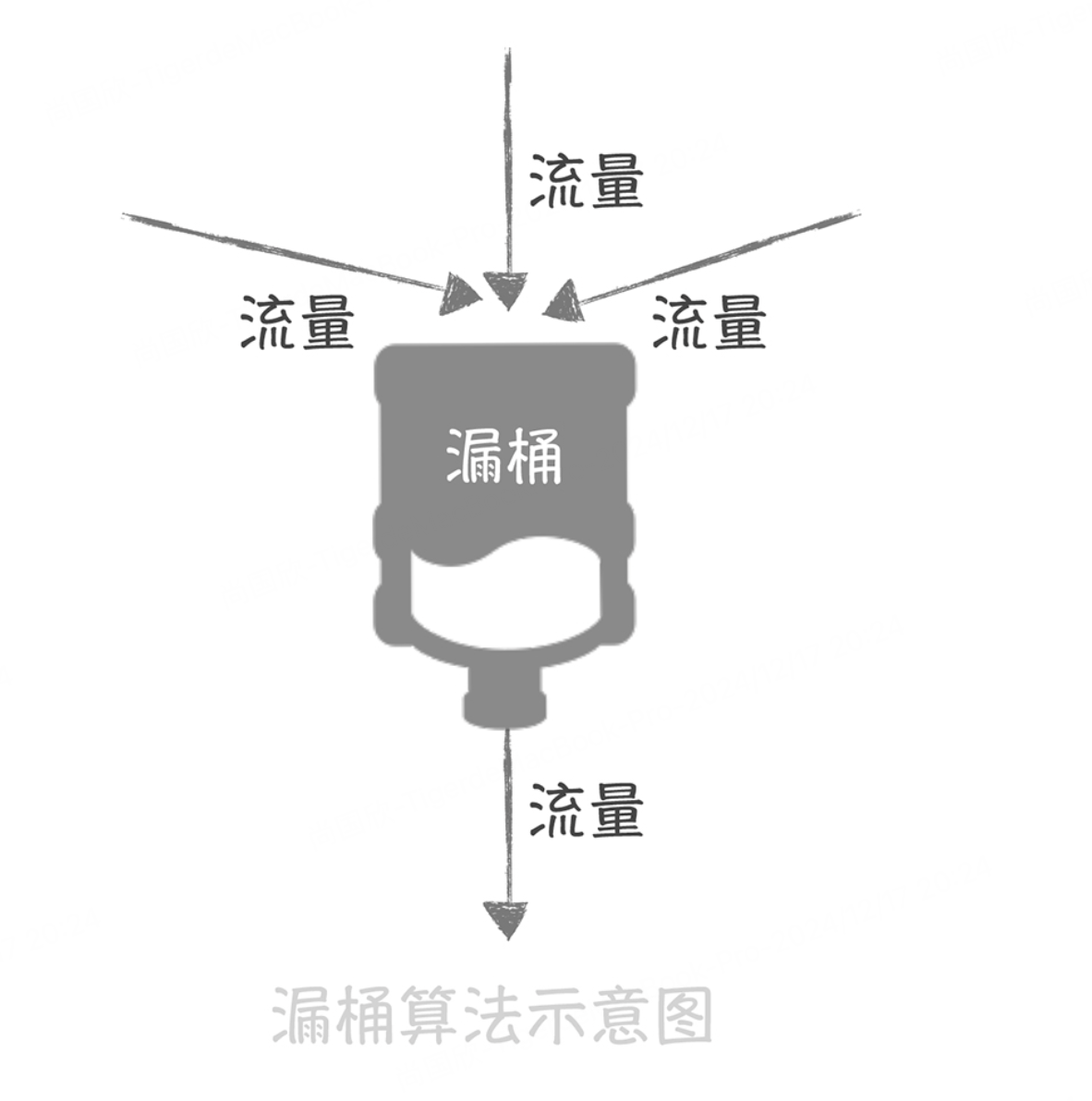
漏桶算法的原理很简单,它就像在流量产生端和接收端之间增加一个漏桶,流量会进入和暂存到漏桶里面,而漏桶的出口处会按照一个固定的速率将流量漏出到接收端(也就是服务接口)。
如果流入的流量在某一段时间内大增,超过了漏桶的承受极限,那么多余的流量就会触发限流策略,被拒绝服务。
经过了漏桶算法之后,随机产生的流量就会被整形成为比较平滑的流量到达服务端,从而避免了突发的大流量对于服务接口的影响。
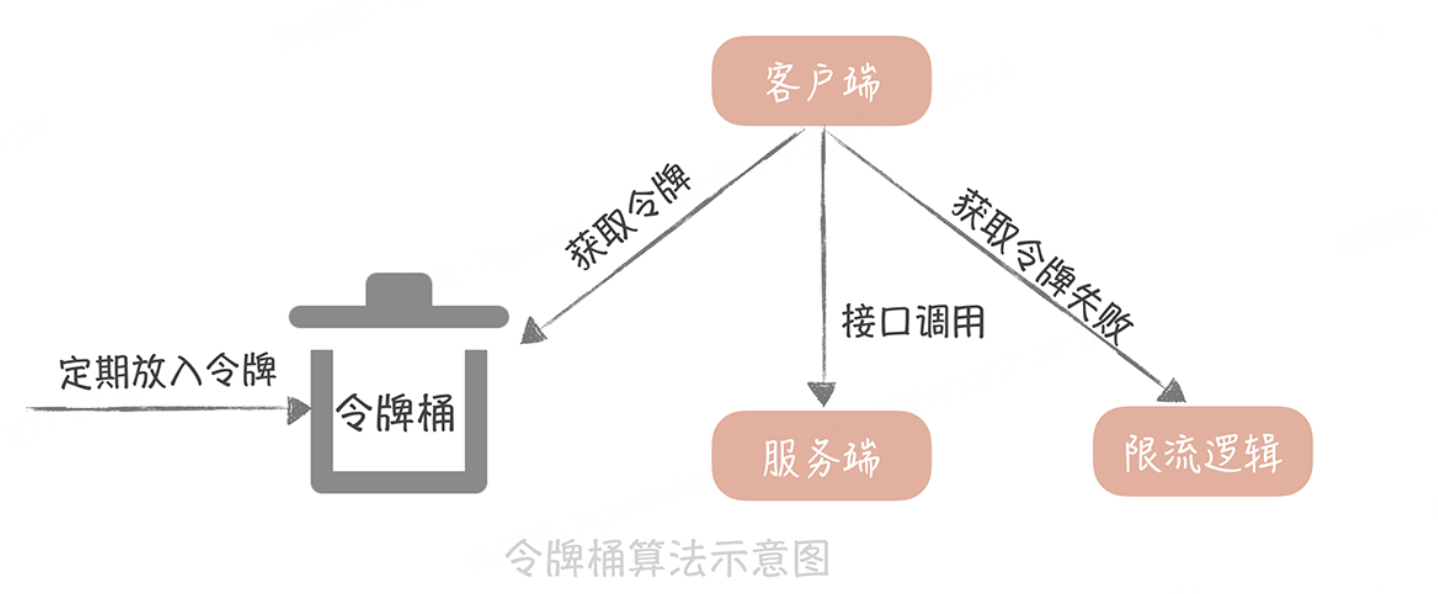
令牌桶算法的基本算法是这样的:
如果我们需要在一秒内限制访问次数为 N 次,那么就每隔 1/N 的时间,往桶内放入一个令牌;
在处理请求之前先要从桶中获得一个令牌,如果桶中已经没有了令牌,那么就需要等待新的令牌或者直接拒绝服务;
桶中的令牌总数也要有一个限制,如果超过了限制就不能向桶中再增加新的令牌了。这样可以限制令牌的总数,一定程度上可以避免瞬时流量高峰的问题。
使用令牌桶算法就需要存储令牌的数量,如果是单机上实现限流的话,可以在进程中使用一个变量来存储;但是如果在分布式环境下,不同的机器之间无法共享进程中的变量,我们就一般会使用 Redis 来存储这个令牌的数量。这样的话,每次请求的时候都需要请求一次 Redis 来获取一个令牌,会增加几毫秒的延迟,性能上会有一些损耗。因此,一个折中的思路是: 我们可以在每次取令牌的时候,不再只获取一个令牌,而是获取一批令牌,这样可以尽量减少请求 Redis 的次数。
限流是一种常见的服务保护策略,你可以在整体服务、单个服务、单个接口、单个 IP 或者单个用户等多个维度进行流量的控制;
基于时间窗口维度的算法有固定窗口算法和滑动窗口算法,两者虽然能一定程度上实现限流的目的,但是都无法让流量变得更平滑;
令牌桶算法和漏桶算法则能够塑形流量,让流量更加平滑,但是令牌桶算法能够应对一定的突发流量,所以在实际项目中应用更多。
限流策略是微服务治理中的标配策略,很难在实际中确认限流的阈值是多少,设置的小了容易误伤正常的请求,设置的大了则达不到限流的目的。所以,一般在实际项目中,我们会把阈值放置在配置中心中方便动态调整;同时,我们可以通过定期地压力测试得到整体系统以及每个微服务的实际承载能力,然后再依据这个压测出来的值设置合适的阈值。