
分库分表是一种常见的将数据分片的方式,它的基本思想是依照某一种策略将数据尽量平均的分配到多个数据库节点或者多个表中。
不同于主从复制时数据是全量地被拷贝到多个节点,分库分表后,每个节点只保存部分的数据,这样可以有效地减少单个数据库节点和单个数据表中存储的数据量,在解决了数据存储瓶颈的同时也能有效的提升数据查询的性能。同时,因为数据被分配到多个数据库节点上,那么数据的写入请求也从请求单一主库变成了请求多个数据分片节点,在一定程度上也会提升并发写入的性能。
数据库分库分表的方式有两种:一种是垂直拆分,另一种是水平拆分。
如何对数据库做垂直拆分
垂直拆分,顾名思义就是对数据库竖着拆分,也就是将数据库的表拆分到多个不同的数据库中。
垂直拆分的原则一般是按照业务类型来拆分,核心思想是专库专用,将业务耦合度比较高的表拆分到单独的库中。举个形象的例子就是在整理衣服的时候,将羽绒服、毛衣、T 恤分别放在不同的格子里。这样可以解决我在开篇提到的第三个问题:把不同的业务的数据分拆到不同的数据库节点上,这样一旦数据库发生故障时只会影响到某一个模块的功能,不会影响到整体功能,从而实现了数据层面的故障隔离。
在社区系统中有和用户相关的表,有和内容相关的表,有和关系相关的表,这些表都存储在主库中。在拆分后,我们期望用户相关的表分拆到用户库中,内容相关的表分拆到内容库中,关系相关的表分拆到关系库中。
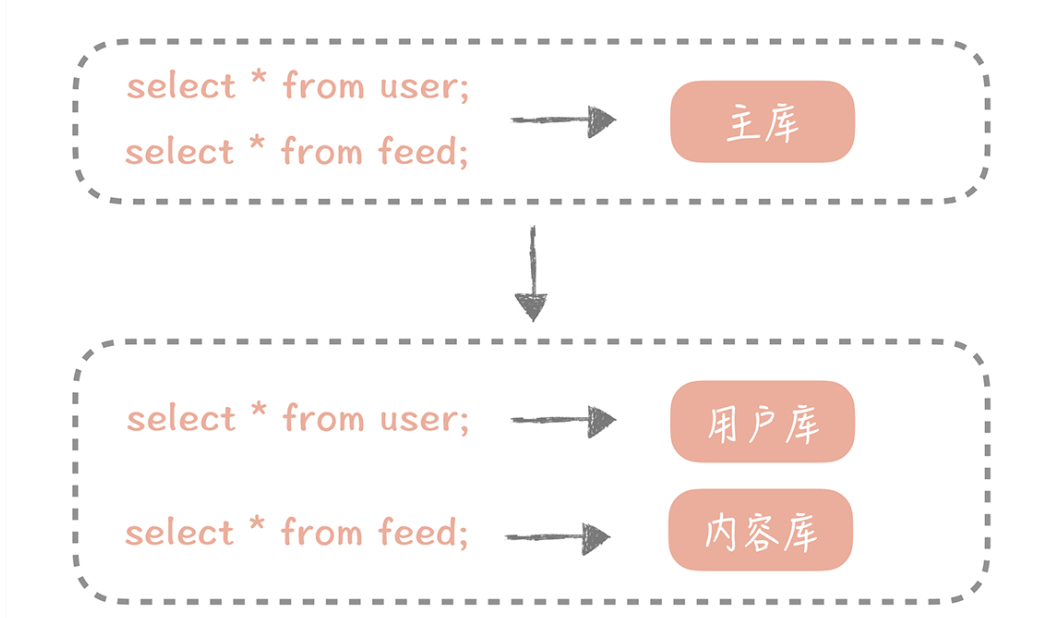
对数据库进行垂直拆分是一种偏常规的方式,这种方式其实你会比较常用,不过拆分之后,虽然可以暂时缓解存储容量的瓶颈,但并不是万事大吉,因为数据库垂直拆分后依然不能解决某一个业务模块的数据大量膨胀的问题,一旦你的系统遭遇某一个业务库的数据量暴增,在这个情况下,你还需要继续寻找可以弥补的方式。这个时候,你需要将数据拆分到多个数据库和数据表中,也就是对数据库和数据表做水平拆分了。
如何对数据库做水平拆分
和垂直拆分的关注点不同,垂直拆分的关注点在于业务相关性,而水平拆分指的是将单一数据表按照某一种规则拆分到多个数据库和多个数据表中,关注点在数据的特点。
拆分的规则有下面这两种:
-
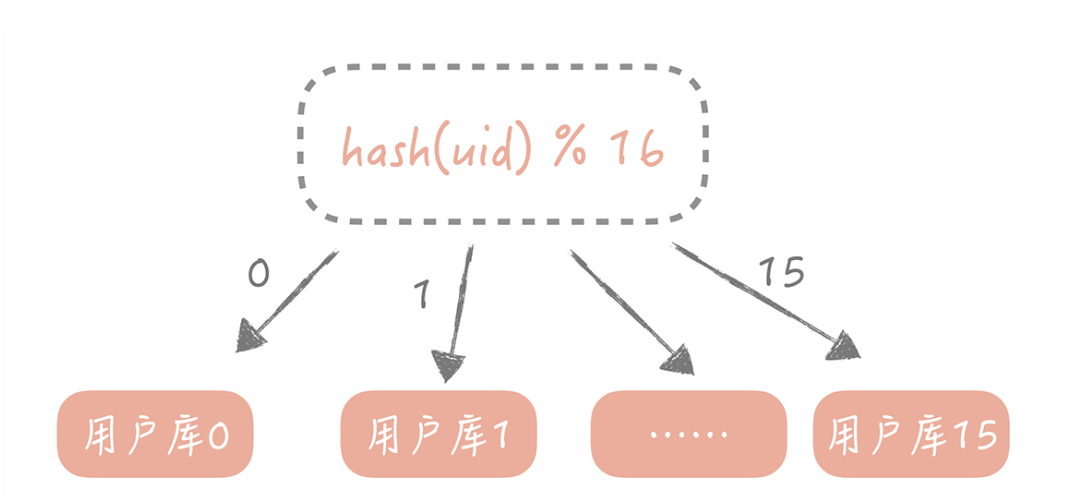
按照某一个字段的哈希值做拆分,这种拆分规则比较适用于实体表,比如说用户表,内容表,我们一般按照这些实体表的 ID 字段来拆分。比如说我们想把用户表拆分成 16 个库,64 张表,那么可以先对用户 ID 做哈希,哈希的目的是将 ID 尽量打散,然后再对 16 取余,这样就得到了分库后的索引值;对 64 取余,就得到了分表后的索引值。
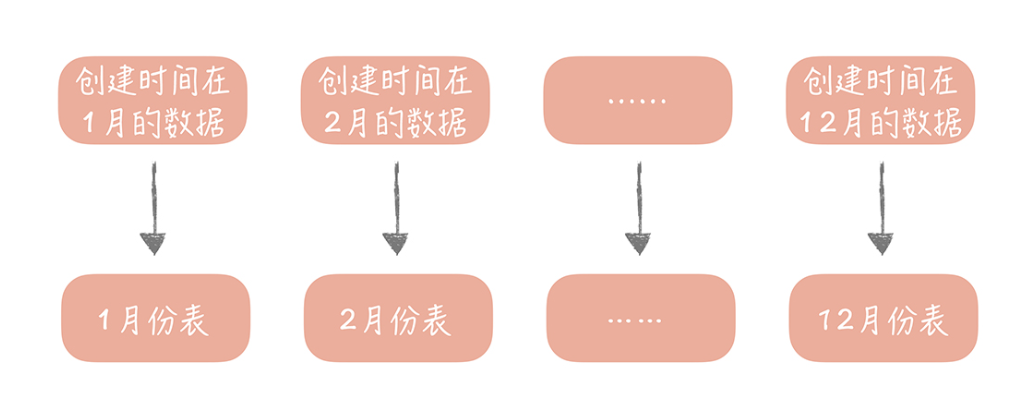
- 另一种比较常用的是按照某一个字段的区间来拆分,比较常用的是时间字段。你知道在内容表里面有“创建时间”的字段,而我们也是按照时间来查看一个人发布的内容。我们可能会要看昨天的内容,也可能会看一个月前发布的内容,这时就可以按照创建时间的区间来分库分表,比如说可以把一个月的数据放入一张表中,这样在查询时就可以根据创建时间先定位数据存储在哪个表里面,再按照查询条件来查询。
一般来说,列表数据可以使用这种拆分方式,比如一个人一段时间的订单,一段时间发布的内容。但是这种方式可能会存在明显的热点,这很好理解嘛,你当然会更关注最近我买了什么,发了什么,所以查询的 QPS 也会更多一些,对性能有一定的影响。另外,使用这种拆分规则后,数据表要提前建立好,否则如果时间到了 2020 年元旦,DBA(Database Administrator,数据库管理员)却忘记了建表,那么 2020 年的数据就没有库表可写了,就会发生故障了。
解决分库分表引入的问题
分库分表引入的一个最大的问题就是**引入了分库分表键,也叫做分区键,**也就是我们对数据库做分库分表所依据的字段。
从分库分表规则中你可以看到,无论是哈希拆分还是区间段的拆分,我们首先都需要选取一个数据库字段,这带来一个问题是:我们之后所有的查询都需要带上这个字段,才能找到数据所在的库和表,否则就只能向所有的数据库和数据表发送查询命令。如果像上面说的要拆分成 16 个库和 64 张表,那么一次数据的查询会变成 16*64=1024 次查询,查询的性能肯定是极差的。
比如,在用户库中我们使用 ID 作为分区键,这时如果需要按照昵称来查询用户时,你可以按照昵称作为分区键再做一次拆分,但是这样会极大的增加存储成本,如果以后我们还需要按照注册时间来查询时要怎么办呢,再做一次拆分吗?
所以最合适的思路是你要建立一个昵称和 ID 的映射表,在查询的时候要先通过昵称查询到 ID,再通过 ID 查询完整的数据,这个表也可以是分库分表的,也需要占用一定的存储空间,但是因为表中只有两个字段,所以相比重新做一次拆分还是会节省不少的空间的。
分库分表引入的另外一个问题是一些数据库的特性在实现时可能变得很困难。**比如说多表的 join 在单库时是可以通过一个 SQL 语句完成的,但是拆分到多个数据库之后就无法跨库执行 SQL 了,不过好在我们对于 join 的需求不高,即使有也一般是把两个表的数据取出后在业务代码里面做筛选,复杂是有一些,不过是可以实现的。再比如说在未分库分表之前查询数据总数时只需要在 SQL 中执行 count() 即可,现在数据被分散到多个库表中,我们可能要考虑其他的方案,比方说将计数的数据单独存储在一张表中或者记录在 Redis 里面。
当然,虽然分库分表会对我们使用数据库带来一些不便,但是相比它所带来的扩展性和性能方面的提升,我们还是需要做的,因为,经历过分库分表后的系统,才能够突破单机的容量和请求量的瓶颈,就比如说,我在开篇提到的我们的电商系统,它正是经历了分库分表,才会解决订单表数据量过大带来的性能衰减和容量瓶颈。
Snowflake

如果你的系统部署在多个机房,那么 10 位的机器 ID 可以继续划分为 2~3 位的 IDC 标示(可以支撑 4 个或者 8 个 IDC 机房)和 7~8 位的机器 ID(支持 128-256 台机器);12 位的序列号代表着每个节点每毫秒最多可以生成 4096 的 ID。
不同公司可以依据自身业务的特点对 Snowflake 算法做一些改造,比如说减少序列号的位数增加机器 ID 的位数以支持单 IDC 更多的机器,也可以在其中加入业务 ID 字段来区分不同的业务。比如不同业务选择某位用不同的值区分,这样可以根据id反推出他是哪个业务id.
一般来说我们会有两种算法的实现方式:
一种是嵌入到业务代码里,也就是分布在业务服务器中。这种方案的好处是业务代码在使用的时候不需要跨网络调用,性能上会好一些,但是就需要更多的机器 ID 位数来支持更多的业务服务器。另外,由于业务服务器的数量很多,我们很难保证机器 ID 的唯一性,所以就需要引入 ZooKeeper 等分布式一致性组件来保证每次机器重启时都能获得唯一的机器 ID。
另外一个部署方式是作为独立的服务部署,这也就是我们常说的发号器服务。**业务在使用发号器的时候就需要多一次的网络调用,但是内网的调用对于性能的损耗有限,却可以减少机器 ID 的位数,如果发号器以主备方式部署,同时运行的只有一个发号器,那么机器 ID 可以省略,这样可以留更多的位数给最后的自增信息位。即使需要机器 ID,因为发号器部署实例数有限,那么就可以把机器 ID 写在发号器的配置文件里,这样即可以保证机器 ID 唯一性,也无需引入第三方组件了。微博和美图都是使用独立服务的方式来部署发号器的,性能上单实例单 CPU 可以达到两万每秒。
Snowflake 算法设计的非常简单且巧妙,性能上也足够高效,同时也能够生成具有全局唯一性、单调递增性和有业务含义的 ID,但是它也有一些缺点,其中最大的缺点就是它依赖于系统的时间戳,一旦系统时间不准,就有可能生成重复的 ID。所以如果我们发现系统时钟不准,就可以让发号器暂时拒绝发号,直到时钟准确为止。